データ活用基盤を構築する際にどのソフトを利用するのか。OSS(オープンソースソフトウエア)やクラウドの普及により、選択肢は増えている。選択時に知っておきたいポイントをまとめた。
「データ活用基盤に関わるエンジニアには、目利きが求められている」。NTTデータの村山弘城 ビジネスソリューション事業本部 AI&IoTビジネス部ソリューションセンタ課長はこう強調する。データ分析基盤の構築には、クラウドサービスやOSSを採用して構築するのが当たり前になっている。
一方で業務システムのトランザクションデータの処理のみを想定した従来のDWH(データウエアハウス)では、DWHに最適化したアプライアンスを利用したり、RDBMSを用いたりするのが一般的だった。米テラデータ(Teradata)や米オラクル(Oracle)などの専業ベンダーは、ハードウエアの力を活用して大容量のデータを検索・分析するアプライアンスを販売。DWHを構築したいユーザーやITエンジニアは、DWH向けに用意された製品の中から要件やコストに合致したシステムを選択するのが当たり前だった。
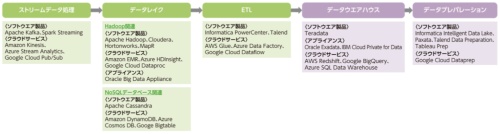
ところが今、データ活用基盤構築の主役がクラウドサービスやOSSに移り、多くの選択肢が登場している。非構造化データを格納するソフトウエアだけでも、OSSの分散処理ツール「Hadoop」やNoSQLデータベース(DB)である「Cassandra」、「Redis」など、複数の候補が挙がる。
Hadoopひとつとっても導入方法や選択肢は多岐にわたる。OSSのHadoopをオンプレミス環境に導入するのか、AWSや米Google、米Microsoftなどが提供するマネージドサービスを選ぶのか、それともHadoopにサポートや可用性を高めるソフトウエアなどを付けた商用製品を使うのか。システムの運用体制やコスト、将来的なデータ量などを踏まえて選ぶ必要がある。
周辺ソフトの充実で使いやすく
データ活用基盤の構築に向け製品やサービスを選ぶ際に、注目すべき動きが3つある。OSSの充実、従来型DWHベンダーのOSSサポートの拡充、そしてETL製品の進化だ。
1つめのOSSの充実では、Hadoopを中心に、様々なソフトウエアが登場している。
頻繁に利用されるのが、「Hive」や「Spark」だ。HiveはSQLを使ってHadoopに格納したデータの検索・分析を可能にするソフトだ。Sparkは分散処理の高速化を支援する。「一般企業での導入は余り進んでいなかったHadoopだが、SQLが利用可能になるなど、利用環境が整ってきたことで導入が進み始めている」と伊藤忠テクノソリューションズ(CTC)の小塚剛 流通・EPビジネス企画室 プロダクトビジネス推進部 プロダクトビジネス推進第3課 主任は話す。
こうしたHadoopを中心にしたデータ活用基盤の構築に使える主要なOSSを、AWSや米Google、米Microsoftなどがマネージドサービスとして提供している。こうしたマネージドサービスを利用すれば、運用の手間が省けるメリットを得られる。
最近では「一般企業の導入が増えてきて、GUIによる管理画面が必要であったり、サポートが必要だったりする。そのため商用版のHadoopを利用するケースも増えている」(CTCの小塚主任)という。Hadoopの商用版は、米クラウデラ(Cloudera)や米ホートンワークス(Hortonworks)、米マップアール・テクノロジーズ(MapR Technologies)などが提供している。
マップアール・テクノロジーズの「MapRコンバージド・データ・プラットフォーム」の場合、分散ファイルシステムとして、Hadoopの「HDFS」を利用するのではなく、マップアール・テクノロジーズの独自製品を提供している。「処理速度を上げたり、耐障害性を高めたりするためだ」とマップアール・テクノロジーズの板垣輝広ソリューションエンジニアは説明する。








