データ活用基盤は、これまでのDWH(データウエアハウス)とは異なる発想で構築する必要がある。ビッグデータをAIで分析するような基盤はどのように構築するのか。押さえるべきポイントを解説する。
ポイント1:スモールスタートで始める
データ活用基盤の構築は、PoC(概念実証)を実施した後に、最低限の機能で始めるのが望ましい。稼働後に、必要に応じて機能を追加していく方針を採ろう。
「必要になるたびに機能を追加する発想で構築すれば、最新の技術を随時、取り入れられるようになる」とウルシステムズの野上恭平シニアコンサルタントは話す。特にAWSの場合、「この3年で日本企業がデータ活用基盤の構築に採用できるサービスが圧倒的に増えてきた」(野上シニアコンサルタント)。
3年前はストレージサービスの「S3」と、DWH(データウエアハウス)サービスのRedshiftを使う構成が一般的だった。それが今は、分散処理ツール「Hadoop」のマネージドサービスである「Amazon EMR」や、ストリームデータの処理を行う「Amazon Kinesis」などデータの処理や蓄積を支援するサービスが数多く登場している。
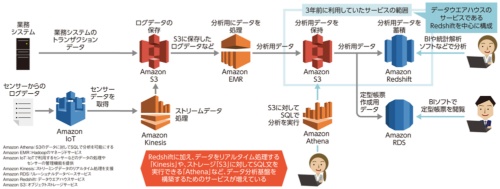
業務システムからのデータだけを収集するDWHであれば、一度構築したら5年以上は使い続けられた。データ活用基盤になった今、一度構築したらそのまま利用するのではなく、随時、新しいサービスや技術を取り込む姿勢が求められる。
ポイント2:製品選択はオープンに
データ活用基盤は、非構造化データなど様々なデータを蓄積する目的で構築するデータレイクや、データレイクのデータを分析用に加工したり集約したりするETL(抽出・変換・ロード)など、複数のツールを組み合わせて構築する。
データ活用基盤は相当の処理能が必要になるので、スケーラビリティが重要になる。スモールスタートで作ったデータ分析基盤は、稼働後に扱うデータ量やデータの種類がどんどん増えると想定される。業務システムのデータと違ってサイジングが難しい分、スケールアウトできる製品やサービスを選択したい。
見落としがちなのは、サービス料金やソフトウエアのライセンス費用の体系だ。CPU単位で課金するソフトウエアをクラウドで採用している場合、スケールアウトすると右肩上がりでライセンス費用が上がる。構築時点の費用だけでなく、スケールアウトを前提にコストを考える必要がある。








