分散処理システムを構築するなら「Hadoop」が有力な選択肢に上がる。Hadoopのスケールアウトする仕組みは問題ないのだが、管理や性能の面で悩みを抱える現場は少なくない。そうした悩みに応える製品が「Hadoopディストリビューション」だ。独自の管理ツールやSQLエンジンを搭載している。
分散処理ソフト「Hadoop」に独自機能を加えた「Hadoopディストリビューション」と呼ばれる商用製品が増えている。米Cloudera(クラウデラ)の「Cloudera Enterprise」、米MapR Technologiesの「MapR」、米Pivotalの「Pivotal HD」などだ。これらは、オープンソースのHadoopを使う際に、ITの現場が直面する問題を解決する。
Hadoopは「遅い」という評価
Hadoopを使っている現場では、大きく二つの問題を抱えることが多い。
一つは管理面である。Hadoopを使えば安価なサーバーを使って分散処理システムを比較的手軽に作ることができる。そのため多数のノード(サーバー)で構成することが多く、導入や運用管理に手間がかかる(図1左)。
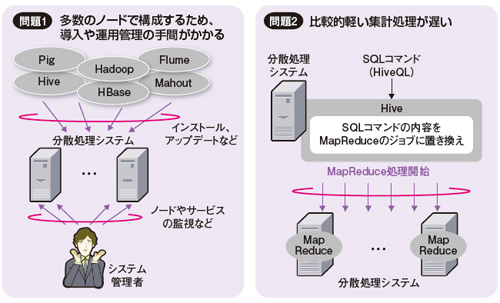
分散処理システムを構成する各ノードには、Hadoopのモジュールをインストールする必要がある。100ノードで構成するなら、同じ導入作業や設定作業を100回繰り返すことになる。さらに導入した後も、パフォーマンスを高めるにはノードの稼働状況を監視しなければならない。
もう一つの問題は性能面である。比較的軽い集計処理をする場合、現場のITエンジニアはHadoopに対して「遅い」と感じている(図1右)。
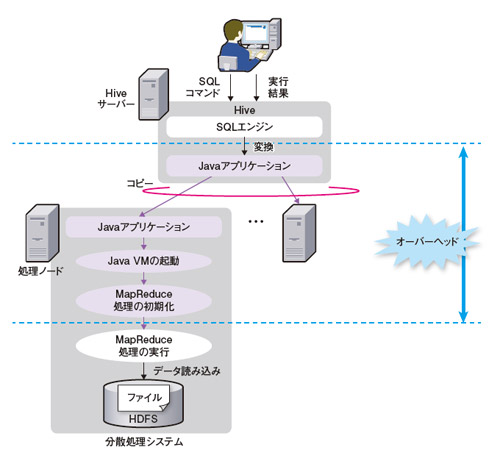
それはなぜなのか。Hadoopで分散処理を実行するにはMapReduceと呼ぶ分散処理のアルゴリズムを実装したJavaアプリケーションを開発する必要がある。ただ集計処理ならJavaで記述するよりSQLで記述したほうが開発しやすい。そこで多くの現場で使われているのが、SQLライクな言語「HiveQL(ハイブキューエル)」で集計処理を実行できる、オープンソースのフレームワーク「Hive」である。
こうした環境では、HiveとMapReduceのオーバーヘッド処理が問題になる。HiveはSQL文を受け取るとJavaアプリケーションに変換する。その後、各ノードでJava VMの起動やMapReduce処理の初期化などを行う必要がある(図2)。重い処理ならこうしたオーバーヘッドは相殺されてしまうが、比較的軽い処理だと「応答が遅い」と感じてしまう。