大規模なデータウエアハウス(DWH)をクラウド上に構築するためのサービスが登場した。処理性能とデータ容量を柔軟に変更できるので、厳密なキャパシティープランニングは不要。ピーク時に合わせて処理性能を確保しておかなくて済む分、コストを低減できる。
米Amazon Web Services(AWS)が2013年2月18日に、大規模データウエアハウス(DWH)を構築するためのクラウドサービス「Amazon Redshift」の提供を始めた。クラウドとしての利点を生かし、柔軟に性能やデータ容量を拡張できるようにしたのが最大の特徴である。同じ2月に提供が開始された、AWS上の仮想サーバーの運用を容易にする新サービス「AWS OpsWorks」と併せて紹介する。
ピーク時に合わせると割高に
一般にオンプレミスの大規模DWHでは、稼働後に性能を高めたりデータ容量を増やしたりするには、サーバーやストレージの構成変更が伴う。それには、調達や動作検証が必要となり、時間がかかる。すぐにはサーバーの処理性能を上げられないので、ピーク時に合わせてサーバースペックを決めなければならなかった。しかも、構築前の設計段階では、稼働後の利用状況やデータ量の増加ペースを見通すのが難しく、余裕を持たせる必要があった。
使う分だけ処理能力を増やせる
Redshiftでは、オンプレミスのDWHのこうした問題を解決できる。必要になった分だけのサーバーリソースやストレージをすぐに調達できるからだ。もちろん不要になればただちに減らすことができる。
性能を柔軟に増減できる理由は、並列処理のアーキテクチャーを採用していることにある(図1)。そのアーキテクチャーは以下の通りだ。
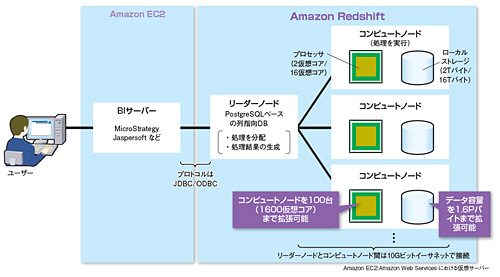
Redshiftは大きく、PostgreSQLベースのDBMSが動作する「リーダーノード」とデータアクセス処理を担当する「コンピュートノード」からなる。コンピュートノードはローカルストレージを備えており、分析対象のデータはここに格納される。
実際の利用時の動作は次のようになる。まず、リーダーノードが、BI(Business Intelligence)サーバーから送られるリクエストを細かい単位に分割し、コンピュートノードに送る。コンピュートノードは、送られてきたリクエストを実行して結果をリーダーノードに返す。処理結果を受けたリーダーノードは、それらを集約してBIサーバーに返す。
複数のコンピュートノードで並列実行するため、「規定の最大台数までは、コンピュートノードを増やすことで処理能力をほぼリニアに向上できる」(アマゾン データ サービス ジャパン ソリューションアーキテクチャ本部 技術統括本部長 玉川 憲氏)。