Apache Hadoopの用途が、単一データの集計から、クロス集計やバッチ処理へと広がっている。それに伴って、規模が拡大して運用管理が大変になる、データ転送に時間がかかるという新たな課題が浮かび上がってきた。Hadoopディストリビューションは、こうした課題に対処する機能を強化している。
「2007年に初めてペタバイトクラスのログデータを集計するHadoopシステムを構築した当時、Hadoopは未成熟で制約も多かった。その後開発が進んで完成度が高まり、Hadoopを採用するユーザーは増えた。さらにここにきて、その用途は広がっている」。
早くからApache Hadoop(以下、Hadoop)システムの構築支援に携わるNTTデータの濵野賢一朗氏(基盤システム事業本部 システム基盤サービスビジネスユニット OSSプロフェッショナルサービス シニアエキスパート)は、こう指摘する。
Hadoopは従来、大量の単一データを短時間で集計したいという要望に応える技術として使われてきた。それが最近は、「複数種類のデータをクロス集計したり、バッチ処理を高速実行したりする用途にもHadoopが使われ始めた」(濵野氏)。それに伴って、新たな課題も浮かび上がってきた(図1)。
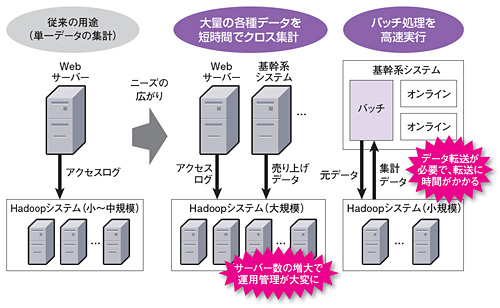
クロス集計でサーバー台数が急増
Hadoopディストリビューションを販売するClouderaのジュセッペ 小林氏(代表取締役 社長)は、「ユーザーは二つの段階を経て、Hadoopシステムでクロス集計をするようになる」と話す。第1段階では、Hadoopシステムをある単一データの集計用に構築する。その有効性が分かると、第2段階として他の単一データもHadoopシステムで集計し始める。その後、複数種類のデータを組み合わせて分析すると新たな発見があることに気付く。
そして、社内に散在する各種データをHadoopに集中させて、例えばWebサーバーのアクセスログと基幹システムの売り上げデータをクロス集計するようになる。小林氏は「欧米では既にクロス集計をするユーザーが多数いるが、日本では最近になって、先進ユーザーがクロス集計を始めた」という。
クロス集計を始めると、データ量や処理量は単一データの集計よりも格段に増える。それに伴って、「分散処理サーバーが数百台から千台以上へと一気に増え、手作業では管理し切れなくなる」(小林氏)。新日鉄ソリューションズの畠山康博氏(技術本部 システム研究開発センター システム基盤技術本部 ミドルウェアグループリーダー 上席研究員)は、「サーバー台数が増えると、機器障害の頻度も高くなる。障害への対処をいかに効率化するかが重要になる」と指摘する。
バッチ処理の用途については現在、有効性を探る検証が盛んに行われている。社内のHadoop検証施設を用いてPoC(Proof of Concept)に携わることが多い伊藤忠テクノソリューションズの小林範昭氏(ITエンジニアリング室 ミドルウェア技術部 DB技術課 課長)は、「売り上げや原価管理といった基幹系あるいは情報系バッチの処理量が想定を超えて増大したユーザーが、解決策としてHadoopに目を付け始めた」と話す。
Hadoopで基幹系システムのバッチ処理を行う際は、連携元の基幹系システムとHadoopの間でデータ転送が必要になる。具体的にはまず、バッチ処理の元データを外部システムからHadoopに転送。バッチ処理完了後に、処理結果を基幹系システムに戻す。こうしたデータ転送に時間がかかることが課題になる。