業務で扱うデータ量の増大や仮想環境の普及によって、プライマリーストレージの容量はいくらあっても足りない状況だ。限られた容量を最大限に生かせる、データ量削減機能を備えたプライマリーストレージが注目を集めている。 現在は製品数が少ないが、今後増加する見込みである。
ストレージに収容するデータ量は増え続ける一方である。例えば、ファイルサーバーに保存する重要な業務データの量が急速に膨らんでいる(図1左)。従来は紙だった帳票や報告書、資料などの文書ファイルの電子化が進んだのに加え、印刷物のスキャンデータ、高精細な画像、動画など数十~数百Mバイトのファイルを業務で扱うケースも珍しくなくなった。さらに最近では、自社サイトのアクセスログやインターネット上の口コミ情報のような、データ量が極めて大きい「ビッグデータ」を蓄積して分析したいというニーズも出てきた。
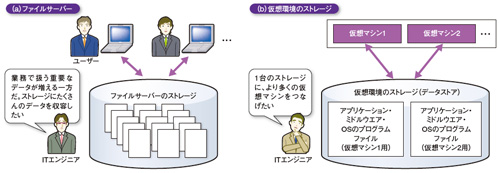
サーバーやクライアントの仮想環境の普及も、ストレージの使用量を増大させている(図1右)。仮想化の対象となるサーバーあるいはPC端末の台数を増やすほど、それだけストレージには仮想マシン用のアプリケーションやミドルウエア、OSのプログラムファイルが増えていく。
だからといって、データ容量を増やすために、ストレージを追加導入するのは難しくなっている。そのコスト負担が意外に大きいからだ。例えばストレージの台数を増やすと、障害の予防や監視、バックアップといった運用コストが膨らむ。大きな災害に備えて遠隔地にバックアップする場合は、ネットワークの増強も必要になる。最近では、こうした運用コストの増大が問題視されるようになっている。ほかにも、追加導入するストレージの設置スペースが足りない、電力消費量を減らさなければならない、といった問題もある。
サーバーやPC端末に影響を与えない
こうした背景から、プライマリーストレージの限られた容量を効率的に利用する「データ量削減機能」が注目を集めている。これは、ストレージ(もしくはサーバーとストレージ間に設置するアプライアンス)のコントローラーで、書き込むデータに対して自動的に重複排除や圧縮をする機能のこと。データを読み出すとき自動的に元に戻すので、サーバーやPC端末に特別なソフトを導入する必要はない。
ここで、重複排除とは、対象データから同一内容のファイル/ブロックを見つけ、そのうち一つだけを残して他のファイル/ブロックを削除すること。圧縮は、PC向けデータ圧縮/解凍ソフトでおなじみのように、データのビット列の規則性を利用し短い符号に置き換えるものだ。この重複排除と圧縮は併用することも可能である。
こうした重複排除や圧縮の機能は、以前から多くのバックアップ用セカンダリーストレージ製品が備えてきた。プライマリーストレージに搭載されるようになったのは、最近のことである。プライマリーストレージへの搭載が見送られてきたのは、データの重複排除・圧縮およびその復元の処理をする際に、コントローラーのCPUに大きな負荷がかかるからだ。しかしここにきてコントローラーのCPU性能が向上したことから、十分実用に耐えられるようになってきた。