サーバー台数が多いほど、お互いを支え合う集団が大きくなり、動作が安定する。不具合解消でバージョンアップが必要になっても、止めずに対処できる。バックアップの標準手法は未確立。自チームで最適なやり方を見つける。
RDBMSと新たなタイプのDBMSでは、システムの運用に大きな差異がある。このPART4では、二つの側面に絞って違いを見ていく。
[新常識7]
大規模になるほど動作が安定
RDBMSを使うシステムでは通常、ディスクの故障に備えてRAID構成にし、サーバー故障に備えてレプリカやスタンバイ機を用意しておく。そして、ディスクが壊れたら交換し、リビルド処理を実行する。また、本番サーバーが故障したらレプリカやスタンバイ機に切り替え、問題を取り除いた後に元の状態に復旧させる―。こうした運用では、RDBを搭載するサーバーの台数が増えるにつれてディスクやサーバーの故障頻度が高まるので、運用管理の手間が増える。
新しいタイプの場合は違う。サーバー台数が増えれば増えるほど、互いに支え合う集団の規模が大きくなって、動作が安定する(図1)。
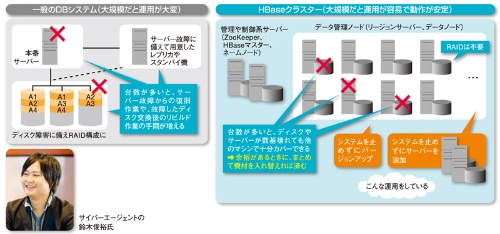
HBaseやCassandra、MongoDBといったDBMSでは通常、ディスクをRAID構成にはしない。ソフトウエアの機能によってデータが複数台のサーバーに冗長に配置されるからだ。サーバーに故障が生じた場合でも、故障したサーバーで行う処理が他サーバーに引き継がれる。
「サーバーが十数台以上あり、余裕を持たせて多めに設置しているなら、1台で障害が起こるたびに対処するのではなく、何台か落ちたらまとめて対処すれば済む」とサイバーエージェントの鈴木俊裕氏(アメーバ事業本部 Ameba Technology Laboratory Software Engineer)は話す。サーバー追加も容易だ。セットアップしたら放っておくだけで、自動的にリバランスが行われ、負荷が割り振られるようになるからである。



