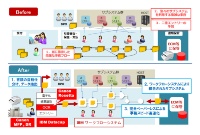
IBM DataCapに日本語OCRエンジンを組み込んだことで、文書キャプチャ時に文字情報を電子化できるようにした。これにより文書のワークフローを自動化できる
(出所:キヤノンマーケティングジャパンと日本IBM)
[画像のクリックで拡大表示]
日本IBMの「IBM DataCap」は、紙文書やデジタル文書を一元管理するコンテンツ管理サーバーソフトである。文書の発生からキャプチャー取り込み、分類、保存といった一連の文書管理プロセスを自動化している。文書が発生した時点で、自動的にこれらからデータを抽出し、リポジトリに格納できる。これにより、文書を入力する作業の負荷を軽減する。
紙文書のスキャンやファクス、メール、モバイル端末などから文書データを取り込み、必要に応じてOCR(光学文字読み取り)スキャンをかけて文字を抽出し、ソート/分類して保存する。特徴の1つは、文字を認識する場所が決まっていない非定型帳票をOCRスキャンする“コグニティブ・キャプチャー”機能を備えること。表示位置やフォントの大きさなどから何の項目なのかを推測する。
日本語のOCR能力を高めるオプション「日本語OCRオプション」を用意した。キヤノンマーケティングジャパンが開発した日本語OCRエンジン込みのソフトウエア開発キット「Rosseta-Stone-Components」を採用したものであり、これを適用すると日本語の活字OCRの認識精度が向上するほか、標準では使えなかった手書きOCRが使えるようになる。
Rosseta-Stone-Componentsについてキヤノンマーケティングジャパンでは、「金融・保険業界での導入実績が多く、申込書などの手書き数字など、日本人特有の手書き文字に強みがある」と説明している。
IBM DataCapの概要
| 用途と機能 | 紙文書とデジタル文書が発生した時点で、自動的にこれらからデータを抽出し、リポジトリで一元管理するコンテンツ管理サーバー |
|---|---|
| 特徴 | ・紙文書のキャプチャと同時にテキストを抽出して電子化できるようにOCRエンジンを組み込んでいること。手書き文字を含めて認識できる ・文字を認識する場所を定義していない非定型の帳票も、文章の内容や表示位置、フォントの大きさ・太さなどから何が書かれているかを推測する“コグニティブ・キャプチャ”機能を備える |
| 日本語OCRエンジン | キヤノンマーケティングジャパンが開発した「Rosseta-Stone-Components」 |
| 価格 | ユーザー数などによって変わるが、現実的なケースで500万円程度から。このうち日本語OCRエンジンのライセンスは100万円程度 |
| 発表日 | 2016年2月8日(日本語OCRオプションの発表日) |
| 出荷日 | 2016年2月9日(日本語OCRオプションの出荷日) |
| 備考 | キヤノンマーケティングジャパンと日本IBMの両者が販売する |