Windowsにおいて「Unicode」は,長らく「使える」けれども「あまり使われない」存在だった。その状況が「Windows Vista」と「the 2007 Microsoft Office」で変わろうとしている。この2製品に付属する「Microsoft IME」で,「WindowsではUnicodeでしか扱えない文字」が,変換候補として頻出するようになったからだ。Unicodeはいよいよ,一般ユーザーが「知らずに使う」存在になるだろう。
マイクロソフトがUnicodeに対応したのは,「Windows 98」と「Windows NT 4.0」からだ。このとき,「JIS X 0212」の「補助漢字」も,エンコーディングにUnicodeを使えばWindowsで利用できるようになった。同時に,JIS X 0212の補助漢字などを使った単語が,Windows OSやMicrosoft Officeに付属する「Microsoft IME」の辞書に登録された。つまり,「Unicodeでしか扱えない文字」,別の言い方をすると「シフトJISでは扱えない文字」が,Microsoft IMEを使って簡単に入力できるようになったのだ。
ただし従来(「Windows XP」と「Office 2003」まで)は,一般ユーザーが「Unicodeでしか扱えない文字」を使うことはまれだった。なぜなら,Microsoft IMEにおいてデフォルトの状態で利用される「標準辞書」には,「Unicodeでしか扱えない文字」がほとんど登録されていなかったからだ。
例えば,Office 2003に付属する「Microsoft IME 2003」の辞書には,「Unicodeでしか扱えない文字」を含む単語が8000単語以上登録されている。ただしこれらのほとんどは,「単漢字辞書」や「人名地名辞書」といった,デフォルトでは利用されない辞書に登録されていた。そして,デフォルトの状態で利用される「標準辞書」には,「Unicodeでしか扱えない文字」を含む単語が37単語しか収録されていなかったのだ。
Microsoft IME 2003で「単漢字辞書」や「人名地名辞書」を利用するには,IMEのツールバーで「変換モード」を「人名/地名」に変更する必要がある(図1)。Microsoft IME 2003のユーザーの多くは,変換モードを「一般」にしていることだろう。従来のWindowsやOfficeでは,Unicodeは「使える」けれども,「あまり使われない」状態だったのではないだろうか。
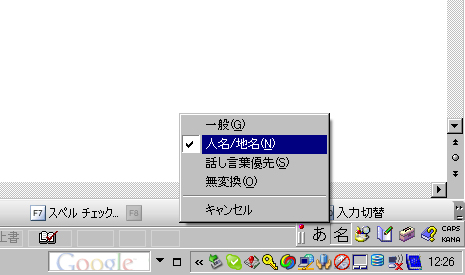 |
| 図1●Microsoft IME 2003で「変換モード」を「人名/地名」に変更した画面 |
Windows VistaとOffice 2007で「Unicodeの単語が頻出」
この状況が,Windows Vistaに付属するMicrosoft IMEと,Office 2007に付属する「Microsoft IME 2007」によって大きく変わろうとしている。ITproの「特番:Windows Vistaの新文字セットが引き起こすトラブル」というサイトで何度も取り上げたように,Windows VistaやOffice 2007は「JIS X 0213:2004」や,2000年12月に政府の国語審議会(現在は文化審議会国語部会)が「表外漢字字体表」という答申で「印刷標準字体」として示した「正しい字体」に対応した。その結果,Windows VistaやOffice 2007の付属IMEで,「Unicodeでしか扱えない文字」を含む単語が変換候補として頻出するようになったのだ。
Windows VistaとOffice 2007のMicrosoft IMEには,もう1つ大きな変化がある。それは「単漢字辞書」や「人名地名辞書」が従来よりも使いやすくなったことだ。こちらの詳細は後述するので,まずはIMEの視点で見た「JIS X 0213:2004」と「表外漢字字体表」への対応について説明しよう。
Windows Vistaに付属する「Microsoft IME」とOffice 2007に付属する「Microsoft IME 2007」では,「JIS X 0213:2004」で追加された文字も入力できるようになり,辞書に新たに740文字が追加された(その結果,Microsoft IMEで入力できる文字の総数は1万670文字になった)。
これに伴い,Microsoft IMEの辞書には「Unicodeでしか扱えない文字」を含む単語が約1700個増え,合計9700単語になった。このうち,デフォルトで利用される「標準辞書」に登録された単語の数は,従来の37単語から大幅に増加して400単語になった。
この400単語には,利用頻度の高い単語がかなり含まれている。一例を図2に示そう。
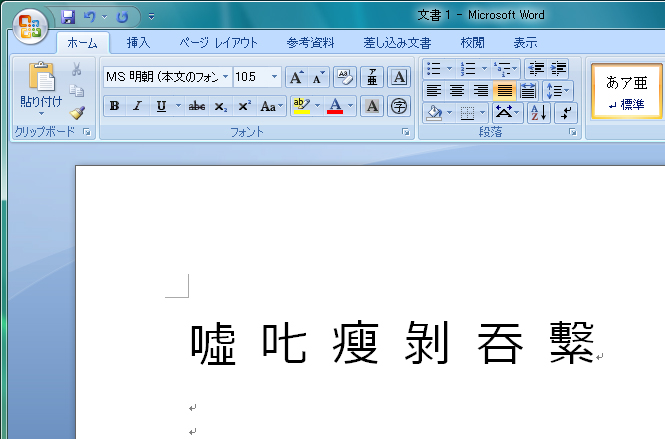 |
| 図2●Windows Vista/Office 2007のIMEの「標準辞書」に含まれている「Unicodeでしか扱えない文字」 [画像のクリックで拡大表示] |
Office 2003のIMEで「うそ」「しかる」「やせる」「はがす」「のむ」「しげる」と入力して変換すると,「嘘」「叱る」「痩せる」「剥がす」「呑む」「繁る」といった漢字が変換候補として出てくる。しかしこれらは,2000年12月の「表外漢字字体表」によって「正しくない漢字」になってしまった。そして図2で示すような「Unicodeでしか扱えない文字」が,「印刷標準字体」という「正しい漢字」になった。
「表外漢字字体表」と「JIS X 0213:2004」の関係や,Windowsの文字セットやフォントの関係は非常に複雑なので,詳しくは既存記事「VistaでUnicode以外の選択肢はなかったのか?──京大の安岡助教授が語る,」や,前述の特番サイトなどを参照していただきたい。
大まかに言うとマイクロソフトは,「表外漢字字体表」で示された「正しい漢字(印刷標準字体)」や「JIS X 0213:2004」に対応するために,Windows VistaとWindows XPに提供する「JIS X 0213:2004対応フォント」に文字を追加したり,既存文字の字形を変更したりした。それに加えてWindows VistaとOffice 2007のMicrosoft IMEで,「Unicodeでしか扱えない文字」を変換候補に登場させるようにしたのである。
「Unicodeの単語」をむやみに増やしたわけではない
ただしマイクロソフトは,「JIS X 0213:2004で使える文字が増えたからといって,今まで使われていなかった漢字を『標準辞書』に大量に追加したわけではない」という。今までの「標準辞書」に含まれる単語を「表外漢字字体表」が示す「正しい漢字(印刷標準字体)」に変換されるように改めただけで「Unicodeでしか扱えない文字」を含む単語が400個にまで増えた,と説明する。
また,Windows VistaとOffice 2007のMicrosoft IMEでは,「Unicodeでしか扱えない文字」には,「環境依存文字(unicode)」という説明が加わるようになった(図3)。図3にあるように,Unicodeでしか扱えない文字が「印刷標準字体」である場合は,その旨も表示される。つまり「印刷標準字体だけれどもUnicodeでしか扱えない文字」と「印刷標準字体ではないけれどもシフトJISで扱える文字」のどちらを使うか,ユーザーに判断を委ねている(従来の字形には「簡易慣用字体」または「デザイン差」という説明が付く)。
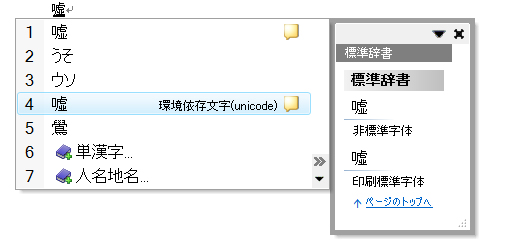 |
| 図3●Windows Vista/Office 2007のIMEでは,「Unicodeでしか扱えない文字」に「環境依存文字(unicode)」という説明が付く |
さらに,Windows VistaとOffice 2007のMicrosoft IMEは,プロパティの設定で「環境依存文字」を変換候補に出さないように設定可能だ。この設定項目は,Active Directoryのグループ・ポリシーを使って一元管理できる。Windows VistaやOffice 2007に移行しても,「社内にシフトJISのアプリケーションが残っているので,社員にUnicodeを使わせない」といったポリシーの運用が可能である。
単漢字辞書と人名地名辞書が使いやすくなった
それでも,Windows VistaとOffice 2007を使うユーザーが,「Unicodeでしか扱えない文字」を使う頻度は今後高まるだろう。なぜなら,Windows VistaとOffice 2007のMicrosoft IMEでは,「Unicodeでしか扱えない文字」を使った単語を9000個以上含む「単漢字辞書」と「人名地名辞書」が,従来よりも使いやすくなったからだ。
Windows XPやOffice 2003までは,「単漢字辞書」と「人名地名辞書」はプロパティで設定を変更しなければ利用できなかった。それが,Windows VistaとOffice 2007では,「単漢字辞書」と「人名地名辞書」がシームレスに利用できるようになった。
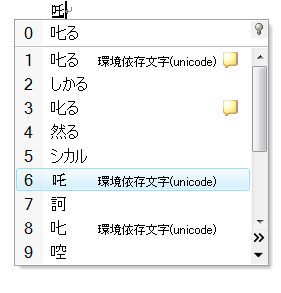
図4を見ていただきたい。変換候補の最後に「6 単漢字」という項目がある。この項目をマウスでクリックしたり,数字の「6」キーを押したりすると,図5のように単漢字辞書に含まれる単語が変換候補に表示される。
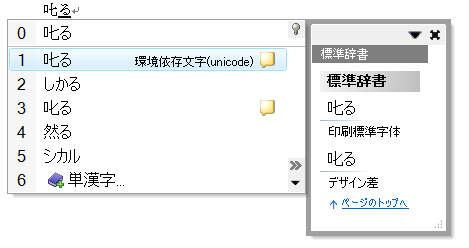 |
| 図4●変換候補の最後に「単漢字」という項目がある |
 |
| 図5●「単漢字」を選択すると変換候補が増える |
「人名地名辞書」も同様である(図6)。「単漢字辞書」や「人名地名辞書」は,これまではMicrosoft IMEに詳しいユーザーしか知らない「隠れた存在」だった。それがWindows VistaとOffice 2007では,常時露出するようになったのだ。多くのユーザーは「環境依存文字(unicode)」という注釈があったとしても,ためらわずにこれらの文字を使うだろう。
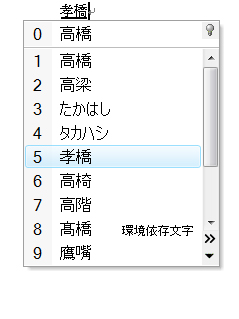 |
| 図6●「人名地名」を選択すると,いわゆる「はしご高」が変換候補に現れた |
いよいよやってきた「Unicode時代」
Microsoft IMEに着目すると,「Windows Vistaの文字セット問題」は,「Office 2007と『JIS X 0213:2004対応フォント』をインストールしたWindows XPの問題」であり,「ただ単に字形が変わる」だけの問題でないことが分かる。
これまでも,Mac OS Xの「ことえり」やジャストシステムの「ATOK」などで,「JIS X 0213:2004」で追加された文字を含む単語の変換が可能であった。そこに圧倒的なシェアを誇るMicrosoft IMEが加わったのだから,不特定多数にアプリケーションを提供する事業者に対する,Unicodeへの移行圧力が強まるのは避けられないだろう。



















































