|
最終回である今回のテーマは,絞り込まれた類似データをチェックして,同一データを決定する作業です。また最後に,名寄せを行うにあたっての注意点やツールについて説明します。
◆名寄せ技術3「類似データの絞り込み」
標準化が済むと,標準化されたデータを突き合わせる作業を行います。名寄せにおける突き合わせとは,同一データかどうかの比較のことです。
完全に一致するデータは問題ありませんが,ある程度一致するデータを同一データととらえるかどうかが,名寄せの場合のポイントです(完全一致を試みるのであれば,名寄せという考え方は必要なく,一般的な付き合せ処理となります)。
「ある程度一致する」というのは人間の感覚的な要素が絡むため,難しいところです。まずは人間の感覚を見てみましょう。図10のデータは,非常に近いデータの例となっていますが,どのデータが同一人物である確率が高いでしょうか?
|
|
| 図10●標準化後のデータの例 (これらは架空のデータであり,実際のデータではありません) |
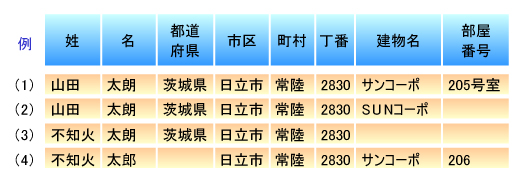
氏名が違ったり,住所が異なったりする場合は,同一人物である可能性は低いと言えるので,非常に影響の大きな要素です。図10では住所はほぼ同じですが,氏名が異なるものがあります。「山田」と「不知火」は別人物と考えるのが普通でしょう。
それに対し,マンション名はよく省略されるので,マンション名の有り/無しは比較対象としてそれほど大きな要素ではなく,片方のマンション名が省略されていても同一人物であるかどうかの判断に影響しません。データが「サンコーポ」と「SUNコーポ」と異なっていても,「山田」と「不知火」の違いほど大きな影響はありません。
都道府県についても,片方の都道府県が省略されていても,それ以降の住所が同じであれば同じであると言えます。つまり,項目ごとにその重みは異なってきます。
次に,図10の(1)(2)の「山田」と,(3)(4)の「不知火」は,それぞれ同一人物であるように見えますが,どちらのほうがより同一人物の可能性が高いと考えますか?
ここでの比較要素として,データの出現頻度というものがあります。つまり,「山田」という姓の人は一般的には多いのですが,「不知火」という姓の人は比較的少ないということです。そのとき,(1)(2)の「山田」よりも,(3)(4)の「不知火」のほうが同一人物であるという確信が持てるのではないでしょうか。「不知火」は非常にまれな氏名(姓)であるために,同じ地域でもその絶対数が少ない場合には,同一人物である可能性が高いと言えます。
この判断を行うにはその出現頻度を数えることが必要です。地域によっては「山田」よりも「不知火」のほうが多いこともあり,逆のことが言えるからです。
以上のように,各項目,各データ値によって互いのデータが「ある程度一致する」という判断が変わってきます。このような感覚を自動化する処理を作るとしたらどうでしょうか。どこまで自動化するかにもよるので,単純比較した例と重み付けを行った例を見てみましょう。
単純比較では,図11のように各項目のデータを比較し,同じであるかどうかをパターン化します。パターン結果に見られるA,B,Eはそれぞれ次のことを意味します。
A:データは同じ B:データは異なる E:データの片方が空
|
|
| 図11●パターンによる単純比較の例 (これらは架空のデータであり,実際のデータではありません) |
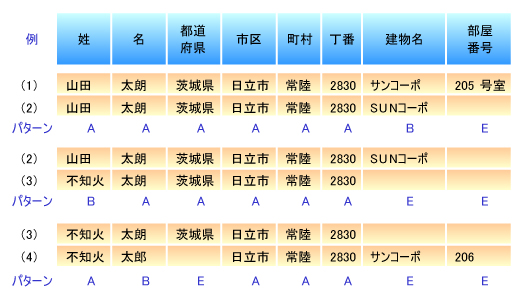
このようなパターンを見つけることで,データの類似性の傾向を見ることができます。ここで「BAAAAAEEのパターンは同一人物ではない」「AAEEAABEのパターンは同一人物である可能性が高い」といった定義をしておけば,ある程度同一人物と考えられるデータの絞り込みを自動化することができます。
一方,重み付けというのは,各項目や各データ値によって類似性の数値化を行うものです。数値化により,比較的複雑な定義をすることができます。
|
|
| 図12●重み付け比較の例 (これらは架空のデータであり,実際のデータではありません) |
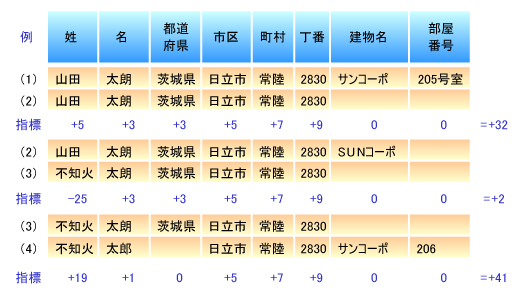
図12の例では,都道府県よりも市区,町村,丁番に重い配点を置いています。各項目に重み付けを行って配点に差を付けることで,項目ごとの重要度を設定できます。
また,姓名のデータでは,データの発生頻度が低いデータが一致した場合は大きな点数を付けています。この場合は「不知火」の発生頻度が低かったために,大きな点数が付けられています。総合的に,(1)(2)の「山田」よりも(3)(4)の「不知火」の一致度が高いことがわかります。
このようなデータの傾向にあわせて重み付けを行うようにプログラム化することで,「類似性が高い」という人間の感覚を数値で表わすことができ,類似データの絞り込みを行うことができます。
以上のように,類似データの絞り込みの段階では,パターン化したり数値化したりして,どれだけ類似性の高いデータかを絞り込む作業を行います。二つの例を見てみましたが,重み付けを行ったほうがより詳細なルールを作れることがわかるでしょう。
しかし,どちらの例を使えば良いかは,実際に格納されているデータ値の傾向によって異なるため,一概に決めることはできないものです。サンプル・データを上手に取得し,データ値を判別するルールをしっかり検討することが必要です。
◆名寄せ技術4「同一データの決定」
同一データの決定では,パターン化や数値化されて絞り込まれたデータが,どの程度一致すれば同一人物と判断するかを決める作業を行います。どのデータも値によってその傾向は異なりますので,どのパターンならOKか,どの点数ならOKかという明確な基準はありません。ここは思い切って決めるしかありません。さて,どうやって決めましょう。
今までは,プログラムでの自動化について考えてきました。しかし,同一データの決定では,完全に自動化するか人間の判断に任せるかは状況次第となります。
まず,今までの名寄せの流れから,数値化されたデータの類似性に対して,一定の基準値を思い切って作ってしまい,どのデータが同一かの判断を完全に自動化することが考えられます。
しかし,この方法は非常に危険です。同一データの判断にぶれがあっても許される場合にのみ採用すべき方法です。今回の例のように,同一人物の特定のような慎重さが求められる作業には適さないのです。基本的にデータは非常に大切なものですから,同一データの判断にぶれがあっても良いという状況は,非常にまれなケースと言えるでしょう。
次に,絞り込まれたデータから同一人物の特定を人間の目で判断することが考えられます。最初はデータ量が非常に多いため,どのデータが同一データかを見極めることが難しかったのですが,調査・標準化・類似データの絞り込みを行うことで,その判断すべきデータが大幅に絞られ,人間の判断が可能な量となる場合もあります。このような場合には,人間が判断するのが良いでしょう。
しかし,類似データの絞り込みまでの作業で,判断すべきデータ量が十分に絞られる状況は珍しいでしょう。ある程度範囲が絞られたとしても,その量はそれなりに膨大です。
その打開策として,絞り込まれたデータのうち,機械的判断で確実に同一データと言えるデータと,人間が判断するべきデータとをさらに切り分けるという方法があります。ここで考えなければならないのは,グレーゾーンの存在です。グレーゾーンとは,データの一致不一致を自動的に判断させることができない微妙な領域のことを言います。グレーゾーンについて,類似データの絞り込みを重み付けで行った例で見てみましょう。
重み付けで類似データの絞り込みを行った結果,各データはその類似性が数値化され,似ているもの順に並べることができます(図13)。
|
図13●類似性の数値化をされたデータ (これらは架空のデータであり,実際のデータではありません)
|
この点数に対して基準値を設け,類似性の数値が基準値以上の場合は同一データ,基準値未満の場合は異なるデータという定義をします。ここでの問題は,この基準値というのがある程度幅を持っているということです。図14を見てください。図14は,全データを類似性の数値で統計をとった結果です。
|
|
| 図14●類似性の数値化結果とグレーゾーン |
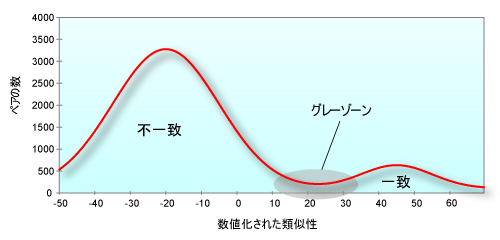
図14の左側(点数が低い側)にある山型の領域は不一致データ,右側(点数が高い側)にある山型は一致データとなります。そして,この二つの山型の間の領域がグレーゾーンです。このグレーゾーンのどこかに基準値を設定して,一致データと不一致データの切り分けをすることになるのですが,図14からも一概に決めてしまうことができないことがわかるでしょう。その名の通りグレーゾーンは,白黒がはっきりつけられない領域なのです。
ここでグレーゾーンのデータをデータ量の観点で見てみると,そこに存在するデータはかなり絞られていますので,この領域のみ人間の目で同一人物かどうかを判断するということが可能となってきます(人間の目で見てもわからない場合は,ハガキや電話で本人に確認を取るなども必要かもしれませんが)。グレーゾーンについてのみ人間が判断し,それ以外は自動化というのが,同一データの決定をする現実的で有効な方法と言えるでしょう。
以上のように,同一データの決定は,自動的に行える領域と人間が判断すべき領域を考えるという作業になります。この結果,同一データの大部分を自動的に割り出すことができ,残りの少数を人間に判断させることを補助することができます。
名寄せを行うにあたって
ここまで,調査→標準化→類似データの絞り込み→同一データの決定,という名寄せ技術を見てきました。しかし,それぞれの処理は順番通りすんなり決まってしまうものではありません。現実には,手戻りが発生することが多いでしょう。
調査の時点では,標準化やマッチングを意識したものである必要がありますし,類似データの絞り込みでの重み付けは同一データの決定に大きく影響します。手戻りは多数発生するでしょうが,データ値の傾向をまっすぐにとらえ,試行錯誤を繰り返していくことが大切です。
名寄せツールもある
以上のように,名寄せには複雑な処理があります。名寄せを行おうとすれば,必ずこのような複雑な処理が発生するので,これを支援するツールも出ています。
例えば,日立製作所が提供している「QualityStage」という製品は,データ・クレンジングや名寄せを支援するツールです。このツールでは,標準化で使用する住所データや氏名データのルールを定義しています。住所や氏名などは,その標準化の方法をある程度決めることができるので,QualityStageのような汎用的なツールがあるのです。このツールを使えば,第2回で説明した図6や図9のような標準化を一気に行うことができます。
ここまで標準化ができてしまえば,突き合わせをすることが容易になるでしょう。この標準化の機能だけでも名寄せツールの効果を実感できます。
類似データの絞り込みでは,ツールごとにバターン化や数値化の方法を持っています。前述のように,類似性の数値化は人間の感覚的な要素が多いためにそれを表現することが難しいので,ツールで「類似性の絞り込み」を自動的に行う場合は,絞り込み内容について注意しましょう。
QualityStageでは,住所データで類似性の数値化をする場合,各項目に重み付けを行っています。また,データの出現頻度に合わせた重み付けをしていますので,データ値の傾向によってその結果が変わってきます。そのため対象のデータで,十分な検証を行うことが必要です。
もしツールで数値化された類似性が期待した傾向にならなかったら,対象のデータがツールの想定している傾向と異なると考え,独自で類似性の数値化を考えたほうが良いかもしれません。これは,名寄せをどの程度厳密に行いたいか,同一データの決定をどのように行いたいかにも絡む問題なので,グレーゾーンと一緒に考えあわせてみることが重要です。
グレーゾーンがどの程度絞り込めるかで,ツールの適用が実用的かどうかが決まってきます。ツールで類似性の数値化を行っても,独自に数値化を作り込んだとしても,グレーゾーンは必ず存在します。とすれば,せっかくツールがあるのなら,ツールの数値化機能をどのように使いこなすかを考えるのが良いのではないかと筆者は考えます。
名寄せは,もともと不明確なデータ同士の類似性を,どこに線を引いて明確に区別するかのルールを決めるという,非常に難しい作業です。また,実データの傾向によりその結果が異なるという,あいまいな世界の作業です。
類似性の数値化の対象となっているデータからサンプルを抽出して事前に検証し,十分とは言いきれないあいまいな点が多少残ってしまったとしても,妥当なところで線引きをするという思い切りが必要です。迷うことはあるでしょうが,時には,古くて着なくなった衣服を捨てるときのような勇気を持って線引きをしましょう。
名寄せの限界
さて,住所データを中心に名寄せを説明してきましたが,名寄せを行いたいデータには他にも様々なものがあります。例えば,工場システムと販売システムで管理している商品を,商品名をキーに名寄せしたいという話があったとします。調査の結果,次のような商品データが同一であることが確認されました。
販売システム:Prius second type X 工場システム:135 Prius 2-X-4D
このデータは,どうやって突き合わせを行えば良いでしょうか。まず,Priusという名前が商品名のキーとなって類似データを切り分けることができるでしょう。このように商品名のキー相当のデータをあらかじめピックアップしておいて,カテゴリ分けをすることが,標準化や類似データの絞り込みによって自動化できる点です。
しかし,これだけでは満足のいく名寄せはできないでしょう。Prius以外のデータを見てみると,各システムで使用しているコードの記述方法が全く違うことに気づきます。そのため,各システムで使用しているコードのルールを熟知している専門家と協力し,二つのコードの標準化と類似データの絞り込みについて,しっかり話し合うことが必要です。
このようなデータの名寄せは,各商品コードについてどれだけ明確なルールを見つけられるかがポイントになります。コード作成ルールの共通点をうまく見つけ,名寄せ作業に結びつけることができれば,名寄せ作業を自動化することができます。
各商品コードを意味のある単位で切り分けて,どれだけルールに共通性があるかを見てみてください。その中に,先に説明した住所データや氏名データの標準化作業のような方法を見つけることができれば,名寄せが行うことができます。
現在,商品コードのようなデータの名寄せ作業は,それぞれのデータに詳しい人間が人間の目で確認してデータの修正したり,データ対応表を作成したりして対応していることが多いようです。
しかし,データが膨大な場合は大変な作業となります。そのため,コードの作成ルールをできるだけ見つけて,グレーゾーンを少しでも小さくするような名寄せを行うことが必要になるでしょう。住所データや氏名データのような理想的な名寄せは難しいかもしれませんが,少しでも名寄せを適用して,人間の作業を楽にしていくことができればうれしいと思います。



















































