|
前回説明した名寄せの各手順について,今回と次回で,個人データの名寄せを例に具体的に説明していきます。
●例題
個人データとして50万件程度のデータがあるとします。このデータは1人で複数登録でき,当初はどのデータが同一人物のものかの特定も必要としていませんでした。しかし,同一人物をまとめて勘定するという新しい要求が出てきたため,名寄せをしなくてはならない状況になりました。
どのようなデータが入っているのか,ある程度の傾向が見られるデータを抽出してみましょう。図3は50万件程度の個人データの中から,データを一部抜粋したものです。
|
図3●抽出した個人データのサンプル (これらは架空のデータであり,実際のデータではありません)
|
このデータをざっとみると,データの形式にばらつきがあることがわかります。このようなデータから同一人物を割り出すためには,どの項目をキーとしてどのような突き合わせをすればよいでしょうか。
データは,図3以外にも膨大にあるので,人間の目で見て判断するのではなく,どのようにしてプログラムで自動的に同一人物を割り出していくかを考えてみてください。人間の目で見れば,4番目の「斎藤 太郎」と最後から4番目の「斉藤 太郎」,最後の「斉藤太郎」というデータは同一人物であると予測できますが,それを自動で判断する場合,どのようなプログラムを用意しますか?
◆名寄せ技術1「調査」
まず,どの項目をキーとして判断していくかを決める必要があります。図3をよく見てみると,「生年月日」は空白データが多数あるため,キーとして有効ではありません。次に「電話番号」は,全く同じ番号であれば同一人物である確率は高いものです。しかし,同一人物でも複数の電話番号を使っている場合は全く別の番号になります。少数ですが空白データも見られるため,優先順位は低くしたほうが良いかもしれません。
「住所」と「氏名」については,空白データはありませんが入力内容にばらつきが見られます。まず氏名データには次のようなばらつきがあります。
- 姓と名の間のスペース記号が様々
- 新漢字,旧漢字が混在している
また,住所データには主に次のような表記のばらつきがあります。
- 都道府県を省略して記述しているものがある
- 建屋表記(マンション,ビル名称)の有無が混在している
- 大字(おおあざ)の表記を省略しているものがある
- 丁目/番地の記述の有無が混在している
- 英数字が全角/半角の記述方法が混在している
- カタカナ表記と漢字表記が混在している
このばらつきが解消できるようならキーとして有効となりそうです。このように,調査の段階では,有効そうなデータ項目とデータ値を見て,キーとする項目を決めていきます。データ値については,後の作業となる標準化への適性?があるかどうかを見ていく必要があります。
図3のような,データの傾向が見られるサンプル・データをうまく抽出し,どの項目をキーとしてその後の名寄せをすれば良いかを決定していくことが調査の段階です(サンプル・データの抽出方法も,調査としては大切な作業です。データの傾向をつかむためには,いかに精度よくサンプル・データを抽出するかが重要だからです)。ここでは,「住所」と「氏名」を名寄せのキー項目として決定することにします。
◆名寄せ技術2「標準化」
標準化は,データのばらつきを解消するために各データを標準的なデータに変換する作業です。各データを他のデータと突き合わせることができるような形式に変換することがポイントです。
では,図3のような住所データや氏名データの標準化とはどういったものでしょうか。標準化を考えるには,データをどのようにして整理するかを考えると良いでしょう。まず,ぱっと思いつくのはソートです。ある程度きれいなデータであれば,ソートすることで同じデータがすぐ隣に来るでしょう。図4は,氏名と住所の項目を抜き出し,住所データでソートした結果です。
|
図4●住所データでソートした結果 (これらは架空のデータであり,実際のデータではありません)
|
ソートした結果,似た住所が整列し,同一データが見やすくなったことがわかります。しかし,最初に目を付けた斉藤太郎さんのデータを見てみると,きれいに隣り合わせにはなっていません。一つの原因として,「東京都」と「杉並区」の間にスペース記号が入っていることが挙げられます。途中にスペース記号や改行文字が入っているとソート結果もばらつきますので,スペース記号や改行文字を除去すると良いでしょう。
|
図5●住所データのスペース記号を除去した結果 (これらは架空のデータであり,実際のデータではありません)
|
スペース記号や改行文字を除去した時点で,少しすっきりするのですが,標準化としては十分ではありません。斉藤太郎さんの例で言うと,「東京都」というデータが抜けている場合があるのです。
ここで思い出して欲しいのは,最終的には各データの突き合わせが必要ということです。「東京都」から記述している住所データと,都道府県を省略しているデータとを突き合わせることはできないので,都道府県名とその他のデータを切り分けなければなりません。
同様に「3丁目4番地」と「3-4」を突き合わせるためには,丁目・番地と切り分けなければなりません。ですので,都道府県/市町村/地名/丁目/番地/建物名の各項目を,トークンとして切り出すのが理想です。その結果,次のようなデータに切り分けるのが理想的な標準化です。
|
図6●標準化された住所データ (これらは架空のデータであり,実際のデータではありません)
|
図6は,住所データを都道府県,市区,町村などの標準的なフィールドにデータを切り分けて,市区・町村・丁目でソートした結果です。都道府県データが十分でないということがわかっていたために,それ以降のデータをソートしています。このような切り分けができれば,各住所は互いに突き合わせできるレベルの標準データとなります。
標準化の結果から述べてしまいましたが,図5のようなデータを図6のように変換する作業をプログラムで自動化しなくてはなりません。このような住所データの標準化を自動化するには,次のものを用意しておく必要があります。
- 都道府県,市区,町村などの住所定義
- 丁目,番地,建物名などの表記パターン
- 定義ファイルを参照して標準化に落とし込むための文字列チェック処理
このようなものを定義,作成して,住所文字列をチェックしていきます。まず,都道府県,市区,町村のチェックです。住所定義を参照しながら,元データを切り出していきます。データの先頭が「神奈川県」となっていれば,都道府県の住所定義と突き合わせて,「神奈川」は県名として切り出します。その次に「横浜市」となっていれば,市区の住所データと突き合わせて「横浜」を切り出します(図7)。
|
|
| 図7●住所データの標準化 (これらは架空のデータであり,実際のデータではありません) |
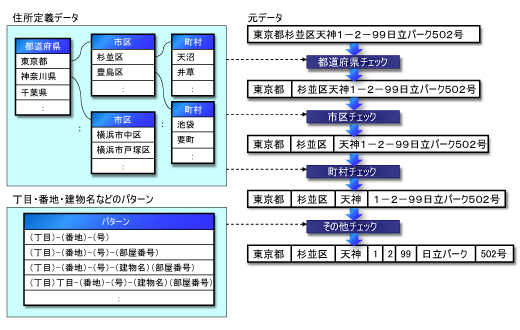
ここで,住所定義を使わなくても,単純にXX県,YY市の文字列を切りだせば良いのでは?と考える人がいるかもしれません。しかし,例えば“市”という文字は,「市川市」や「四日市市」などのように,YYの中にも存在する可能性があるので,単純な切り出しはできません。市区名をあらかじめ定義しておく必要があります。
次に,丁目,番地,建物名などのチェックを行います。この定義は,都道府県,市区,町村などの定義ファイルを用意するのではなく,表記パターンを用意しておくのが良いでしょう。ハイフン(-)で区切るパターンや,XX丁目YY番地といった記述をするパターンがあるので,それぞれに基づいたチェックを行えば切り分けができるでしょう。
このようにデータを切り分けて,標準フィールドに値を埋めていくのが,住所データの標準化です。
氏名データの標準化はもう少し単純で,スペース記号や改行文字を除去した後,姓,名の切り分けをすれば良いでしょう。しかし,調査の段階で「新漢字,旧漢字を混在して用いているものがある」というばらつきを見つけていました。そのため,新旧漢字の対応表を用いて,どちらかの文字に統一しておくのが良いかもしれません。そして,氏名一覧というものを用意しておけば,図8のような処理で姓と名の切り分けができます。
|
|
| 図8●氏名データの標準化 (これらは架空のデータであり,実際のデータではありません) |
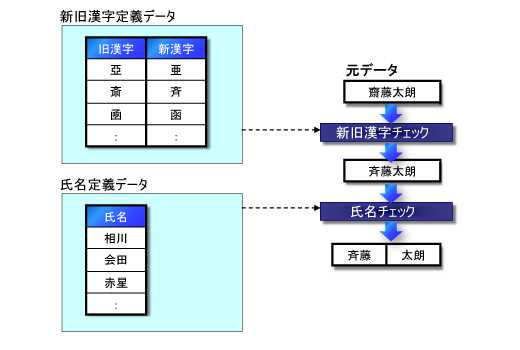
しかし,それでも完全な標準化が行えるわけではありません。「南総一郎」という氏名があったとすると,「南 総一郎」とするか「南総 一郎」とするかは完全には判断できないからです。このようなデータは完全に切り分けが行えないため,例外的に保留するということも考慮しておくと良いかもしれません。この例外処理も入れておけば,図9のような結果を得ることができるでしょう。
|
図9●標準化された氏名データ (これらは架空のデータであり,実際のデータではありません) |
以上のように,データ形式のばらつきを吸収するように,データを切り分けて細かいフィールドに分けていく作業が標準化です。標準化を終えたら,標準化されたデータを突き合わせて,同一データを決定します。それについては次回説明します。



















































