 |
| 図8●VistaとXP以前とで字体が変わった第四水準漢字14字 |
前報では,JIS X 0213の第一水準~第三水準漢字7614字について,Vistaで新たに採用された日本語フォントセットであるメイリオとXP以前のMSゴシックを見比べ,7614字のうち325字*が,VistaとXP以前との間で文字化けする(ここでは本来表示されるべき文字の形が少し違ったものが表示されるケースも“文字化け”として扱う)ことを報告した。今回は,残る第四水準漢字2436字と非漢字1183字について報告する。
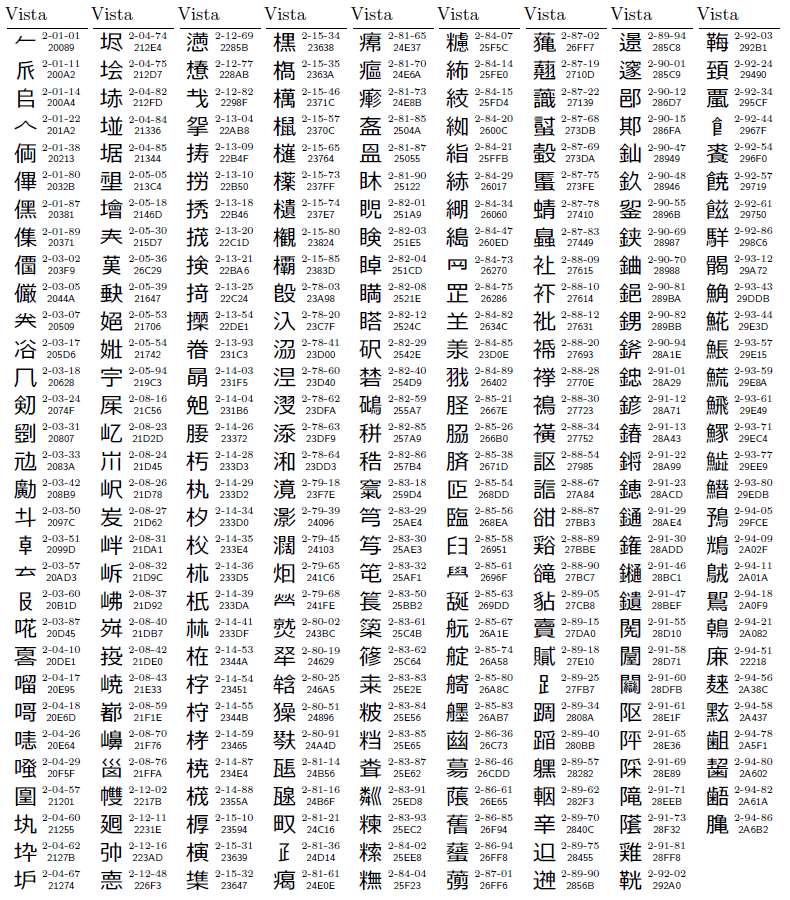
第四水準漢字2436字のうち,Vistaの字体がXP以前と明らかに異なっているのは,14字ある。図8に一覧を示す。図の中で「2-08-68」というように書いているのはJIS X 0213の面区点番号,「5DB2」の方はUnicodeである。これを見るとわかるように,例えば「山かんむりに雋」という漢字をVista上で入力したつもりでも,そのデータをXP以前のパソコンに持っていくと「屮かんむりに雋」に化けてしまうのだ。
残り2422字のうち図9~11に示す722字は,Vistaでは表示できるが,XP以前では表示できない。特に,図9に示した277字は,Unicodeの弱点とも言うべきサロゲート・ペア(前報のカコミ記事参照)を使わなければならないので,XP以前のパソコンに持っていくと,ソフトウエアによってはちゃんと処理されない可能性が高い。結局,第四水準漢字で問題がないのは,これら736(14+722)字を除いた,1700字だけということになる。
 |
| 図9●Vistaで表示できてXP以前で表示できない第四水準漢字722字(うち追加漢字面の277字) [画像のクリックで拡大表示] |
 |
| 図10●Vistaで表示できてXP以前で表示できない第四水準漢字722字(うち拡張Aの145字) |
 |
| 図11●Vistaで表示できてXP以前で表示できない第四水準漢字722字(うち300字) [画像のクリックで拡大表示] |
 |
| 図12●VistaとXP以前とで字体が変わった非漢字11字 |
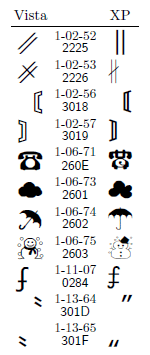
では,非漢字はどうだろう。JIS X 0213の非漢字1183字のうち,Vistaの字体がXP以前と明らかに異なっているのは,11字ある(図12)。ただし非漢字については,字体の違いをどこまで許容するかというのは結構難しい問題であり,人によっては,これ以外にも気になる文字があると思う。
非漢字の残り1172字のうち,図13~14に示す187字は,Vistaのメイリオでは表示できるが,XP以前のMSゴシックでは表示できない。ここで「XP以前のMSゴシック」と限定したのには意味がある。「Arial Unicode MS」や「Lucida Sans Unicode」などのフォントを使うと,XPパソコンでもこれら187字のうちいくつかは表示できる。あるいは,XPパソコンにVista相当のフォントをインストールすれば,これら187字はすべて表示できてしまう。しかし,表示できてしまうという点にこそ,実は問題があるのだ。
 |
| 図13●Vistaで表示できてXP以前で表示できない非漢字162字 [画像のクリックで拡大表示] |
 |
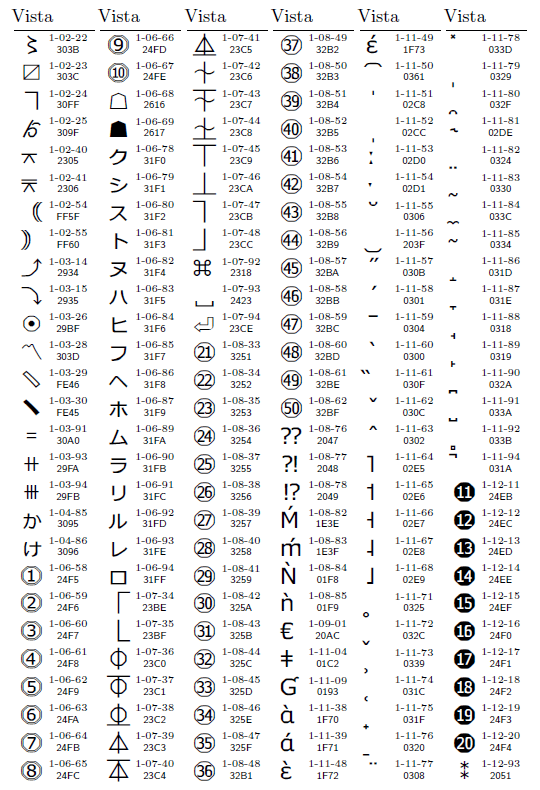
| 図14●文字合成を必要とする非漢字25字 |
図14に示す25字は,Unicodeの文字を2つ合成することによって,1文字を表している。例えば「プ」(小書きのプ)は,「フ」(小書きのフ)を表すUnicode「31F7」と,合成用半濁点「309A」を並べて,「31F7 309A」というUnicode列で「プ」(小書きのプ)を表現している(図15)。ありていに言えば,メイリオは「31F7 309A」というUnicode列に対して,1文字「プ」を表示するのである。これは,XPにVista相当のフォントをインストールした場合でも,同じことだ。
 |
| 図15●Unicodeにおける文字合成 |
では,「31F7 309A」というUnicode列を,各ソフトウエアは1文字として扱うべきなのか。それとも,やっぱりこれは2文字として扱うしかないのか。あるいは,1-11-69の直前に1-11-64を挿入して「02E5 02E9 02E5」というUnicode列になった場合,これはそのまま1-11-64と1-11-69として扱うべきなのか。それとも1-11-70と1-11-64という,全く異なる文字列として扱わざるを得ないのか(図16)。
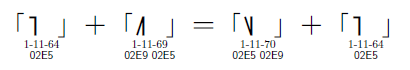 |
| 図16●Unicodeの文字合成におけるJIS X 0213との乖離 |
しかも,文字合成の問題は,図14の25字にとどまらない。小書きの「プ」が文字合成で表現されるならば,普通の「プ」はどうなのだろう。文字合成しなくてもいいのだろうか? 結論から言うと「プ」は,文字合成でも表現できるし,文字合成でない方法でも表現できる。
すなわち,「フ」を表すUnicode「30D5」と,合成用半濁点「309A」を並べて,「30D5 309A」というUnicode列で「プ」を表現できる。あるいは,Unicode 1.0以来ずっと使われてきた「30D7」で「プ」を表現してもかまわない(図17)。実際メイリオは,「30D5 309A」に対しても「30D7」に対しても,同じ「プ」を表示する。
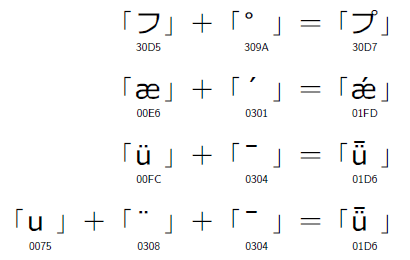 |
| 図17●Unicodeにおける不幸な文字合成 |
 |
| 図18●文字合成を使っても使わなくてもよい非漢字200字 [画像のクリックで拡大表示] |
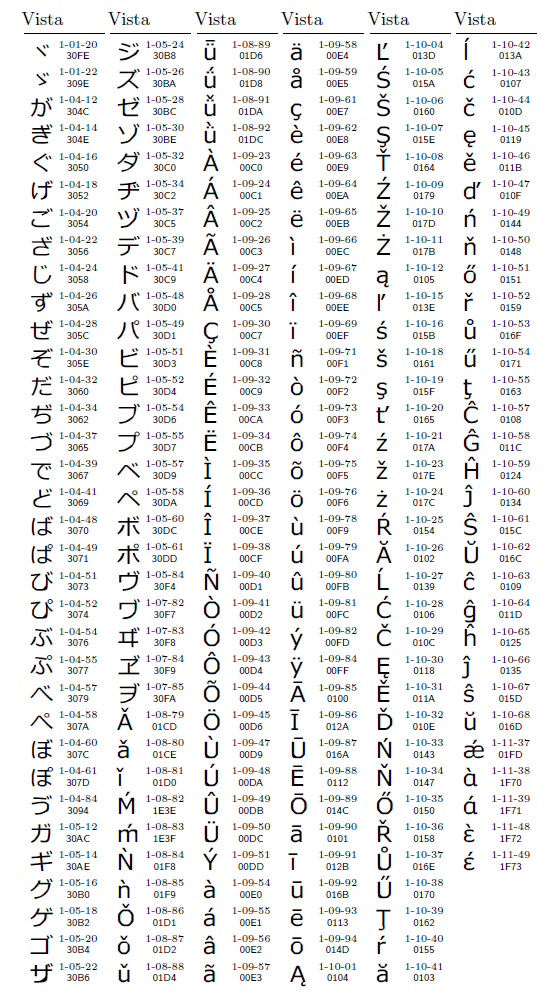
「プ」と同じように,文字合成を使っても使わなくてもよい字が,JIS X 0213の非漢字には200字ある。図18にこれら200字を示す。中でも強烈なのは1-08-89,1-08-90,1-08-91,1-08-92の4字だ。例えば1-08-89に対しては,「0075 0308 0304」と「00FC 0304」と「01D6」の3種類の表現がありうる(図17)。1-08-89の文字をUnicodeで扱うには,この3種類の表現を全て同一視する必要がある,ということだ。
JIS X 0213の非漢字についてまとめると,非漢字1183字のうち,VistaとXP以前との間で問題がないのは,793字だけだ。図12~14の198字については,VistaとXP以前との間で文字化けする。しかも,この文字化けを防ぐべく,XPパソコンのフォントをVistaと同じものに入れ換えると,1183字すべてを表示できるようにはなるが,今度は,図14と図18の225字に対して,文字合成を考慮に入れなければならない。どちらにせよ,かなり難しい対応を強いられるのは間違いない。
では,ここまで苦労して,JIS X 0213の文字1万1233字すべてを,VistaとXPの両方で使いたいのか。それとも,そこそこの対応で,使える文字だけを何とか文字化けさせずに使っていくのか。複雑きわまりないUnicodeへの対応を行う前に,どの文字が実際に必要なのか,十分な考慮が必要だろう。それによって,Vistaの文字化け問題への対応も,おのずと変わってくるはずだから。
|
| 【訂正】前報「Vistaで化ける字,化けない字」の訂正にともない,本文を6個所(*の個所)修正しました。2007.01.23 |



















































