11月30日に企業向けには出荷が始まったWindows Vista。そのVistaで,“文字化け”が起こるらしい。文字化けといっても,Webアクセス中にたまに見かける全く読めない文字の羅列になることはほとんどなく,その多くは似た文字が表示される程度である。ここでは,本来表示されるべき文字の形が少し違ったものが表示されるケースも“文字化け”として扱う。
Microsoftは,Windows 98日本語版の発売以来,Windows 2000,Windows Me,Windows XPまでCP932(本名はWindows Codepage 932,いわゆるMS漢字コード)とJIS X 0212をサポートしてきたが,最新のWindows VistaではJIS X 0213に乗り換えた。いや,乗り換えたというのは,ちょっと語弊がある。CP932とJIS X 0212に加えて,JIS X 0213もサポートした。ただ,その際にJIS X 0213を前面に押し出す形になったというのが,説明としてイイセンではないだろうか。ただし,JIS X 0213を前面に押し出したとはいえ,CP932のサポートもやめられないので,VistaではUnicode上でJIS X 0213の文字を書けるようにした。何だか話がヤヤコシクなってきた。
このヤヤコシサのせいか,Windows Vistaの“文字化け”に関して,チマタでは怪情報が乱れ飛んでいる。しかし,キチンと調べればわかることだ。Vistaのフォントセットの一つであるメイリオと,Windows XPのMSゴシックを,一字一字見比べていけばすぐにわかる。とりあえずJIS X 0213の第一水準~第三水準漢字である7614字について,筆者が見比べてみた結果を,ここに公表しておこう。
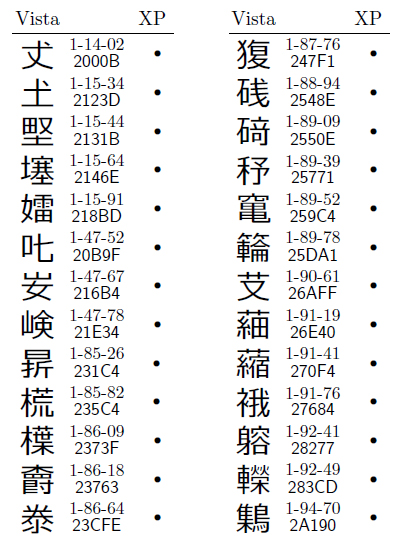
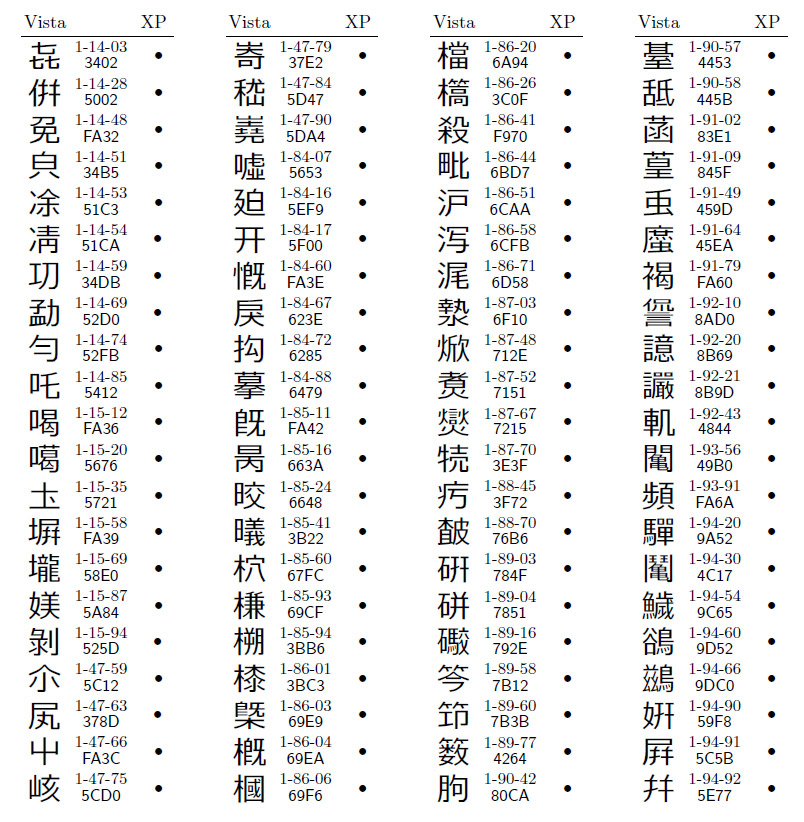
第一水準漢字2965字のうち,Vistaの字体がXPと明らかに異なっていたのは,116字だった。図1と図2に一覧を示す。図中で「1-33-25」というように書いているのはJIS X 0213の面区点番号,「564C」の方はUnicodeである。この例でいくと,「口へんに曾」という漢字をVista上で入力したつもりでも,そのデータをWindows XPパソコンに持っていくと「口へんに曽」に化けてしまう,ということである。第一水準漢字で化けるのは,この116字だけで,残りの2849字に関しては問題なかった。常用漢字は全く問題ないし,チマタで話題の「鴎」や「繋」も化けなかった。
|
|
図1●Windows VistaとXP以前とで字体が変わった第一水準漢字116字(うち人名用漢字80字)
[画像のクリックで拡大表示] |
|
|
| 図2●VistaとXP以前とで字体が変わった第一水準漢字116字(うち36字) |
ただ,化ける116字中に,人名用漢字が80字含まれていた(図1)。さっきから,チマタ,チマタとカタカナで書いているのは,漢字で書くと化けてしまうからだ(図1の1-25-11)。Vistaの字体の方が人名用漢字(子の名に使える漢字)としては正しくて,Windows XPの字体はダメである。「巷」も,下が「巳」のVista の方が正しくて,XPの「己」は間違いだ。こんな漢字が80字もあると,さすがに対処が大変かもしれない。
第二水準漢字3390字中では,Vistaの字体がWindows XPと明らかに異なっていたのは16字*だった(図3)。3374字*は大丈夫だ。化ける16字*中では,「燿」だけが人名用漢字である。
|
|
| 図3●VistaとXP以前とで字体が変わった第二水準漢字16字 |
第三水準漢字1259字のうち,Vistaの字体がWindows XPと明らかに異なっていたのは10字*だった(図4)。では,残りの1249字*は大丈夫かというと,そうでもない。図5~7に示す183字*は,Vistaでは表示できるが,Windows XPでは表示できない。JIS X 0213の1-14-31に当たる「にんべんに曾」をVistaで入力しても,そのデータをWindows XPパソコンに持っていったら何も表示されない。まあ,第一水準で常用漢字である「僧」を代わりに使えば文字化けなどは起こらないが,人名用漢字として「にんべんに曾」をどうしても使いたい場合もある。その場合はVista限定にするなどの注意が必要だ。
|
|
| 図4●VistaとXP以前とで字体が変わった第三水準漢字10字 |
|
|
図5●Vistaで表示できてXP以前で表示できない第三水準漢字183字(うち人名用漢字73字)
[画像のクリックで拡大表示] |
|
|
| 図6●Vistaで表示できてXP以前で表示できない第三水準漢字183字(うち追加漢字面の26字) |
|
|
図7●Vistaで表示できてXP以前で表示できない第三水準漢字183字(うち84字)
[画像のクリックで拡大表示] |
また,図6に示した26字は,Unicodeの弱点とも言うべきサロゲート・ペアを使わなければならないので,Windows XPパソコンに持っていくと,ちゃんと処理されない可能性がある(カコミ記事「サロゲート・ペアとは」を参照)。
第三水準漢字1259字のうち,文字化けの可能性があるのは図4~7の193字*だけで,残りの1066字*は問題がなかった。チマタで話題の「鷗(Unicode:9DD7)」や「繫(同7E6B)」も化けなかった。しかも,システム上の不都合が発生するのは,サロゲート・ペアがらみの26字(図6)だけだ。
ここまでをまとめると,JIS X 0213の第一水準~第三水準漢字7614字のうち,325字*が,VistaとWindows XPとの間で文字化けする。残り7289字*は問題がない。しかも,文字化けする325字*のうち,純粋に文字コードの問題なのは図6の26字だけで,残り299字*(図1~5,7)は単にフォントの問題である。つまり,この299字*に関しては,Windows XPパソコンでも,フォントを入れ換えればVistaと同じ字形にできる。
今回は第一水準~第三水準漢字しか調査しきれなかったが,実は第四水準漢字と非漢字には,もう少したくさんの文字化けが発生しそうだ。第四水準漢字2436字のうち,サロゲート・ペアによる文字コードがらみの問題が277字あり,それを含む800字弱で文字化けが発生する。非漢字1183字に関しては,文字コードがらみの問題が25字あり,それを含む200字弱で文字化けが発生するようだ。これらについては,筆者も早急に調査してまとめたいと考えているので,続報をお待ちいただきたい。
Unicodeは元々16ビットの文字コードだ。16ビットのコードを,16進数で書くと4桁になる。ところが16ビットしかないと,どうやっても最大6万5536字しか扱えない。一方,漢字は7万字も8万字も収録したいので,16進数4桁では無理になって,とうとう16進数5桁のところにハミ出ざるを得なくなった。
Unicodeの方では,16進数5桁,つまり20ビットをそのままでは扱えないので,16ビットのコードを2つ組み合わせることで急場をしのいだ。例えば「2000B」であれば,実際には「D840 DC0B」という組み合わせで処理される。これがサロゲート・ペアだ。この場合には,1文字が16ビットではなく32ビットになる。
「1文字=16ビット」と決め打ちになってるソフトウエアは,たちどころに処理が崩壊してしまう。Windows XPのメモ帳ですら「D840 DC0B」を2文字と認識してしまう(Deleteは大丈夫だが,BackSpaceはダメだ)し,ほかのソフトウエアでも似たようなことが起こったりする。
|
|
| 京都大学人文科学研究所附属漢字情報研究センターの助教授。1965年生。1990年京都大学大学院工学研究科情報工学専攻修士課程を修了し,同年京都大学大型計算機センター助手に就任。1997年に同助教授となる。2000年に現職に就き現在に至る。京都大学博士(工学)。文字コードに関して多数の著書がある。 |
|
| 【訂正】記事公開時には図3に12字,図4に9字,図5に71字を収録していました。しかし,その後の調査の結果,これらの図から,JIS X 0213の面区点番号で「1-50-42」「1-62-54」「1-63-01」「1-78-28」「1-86-52」「1-84-14」「1-86-27」の7字が漏れていたことが判明しました。お詫びして追加/訂正いたします(図3~5,および本文の*が修正個所です)。2007.01.23
|