携帯電話事業者の米Sprintは、実際に起こったシステム障害のすべてを、いずれも30分前に知ることができたという。なぜこのようなことが可能になったのかと言えば、統計理論のおかげである。情報システムの応答時間の計測値をソフトウエアで統計処理させたのである。
ある国内金融機関でも、統計理論が力を発揮した。統計理論の活用で、実際に起こったシステム障害の原因を、ログデータ変換などの事前作業を含めて、わずか半日で突き止めたのである。従来、人手で障害の原因を解析していたときには、データベースやWebなど各分野の専門家を集めて2週間を要していた。
このように、統計理論を活用すると、性能の計測値を入力するだけで、システム障害の予兆を検知したり、障害の原因を早期に究明したりできるようになる。従来型の性能監視手法(計測値がしきい値を超えるかどうかを監視する手法)では発見しにくい異常な計測値を、統計計算で検知できるのである(図1)。
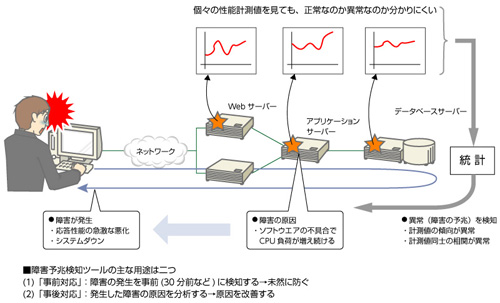
ベンダー各社が障害予兆検知ツールを発売
実際にここ数年、統計理論を活用してシステム障害の予兆を検知するツールが登場してきた(表1)。2009年10月にNECが「WebSAM Invariant Analyzer」、2011年1月に富士通が「Proactnes II SM」、2011年7月に日立製作所が「JP1/IT Service Level Management(JP1/IT SLM)」、2012年3月に日本ヒューレット・パッカード(日本HP)が「HP Service Health Analyzer(SHA)」をそれぞれ出荷開始した。
| ベンダー/製品名 | 特徴 | 価格(税別) |
|---|---|---|
| NEC WebSAM Invariant Analyzer | CSVファイルなど任意のデータを対象に、任意の二つの計測値同士の相関をモデル化 | 通常版が1150万円。計測値を1000個までに限定したエントリ版が400万円 |
| 日本ヒューレット・パッカード HP Service Health Analyzer | 性能監視ソフト群から各種データを取得。素のデータに対する統計処理をシステム構成情報などで補正してモデル化 | 800万円から |
| 日立製作所 JP1/IT Service Level Management | パケットキャプチャにより、Webアプリケーション(HTTP)の応答時間、スループット、エラー率を取得。これらの傾向をモデル化 | 可視化モジュールが200万円。HTTPパケット情報収集モジュールが60万円から |
| 富士通 Proactnes II SM | パケットキャプチャで収集したIPヘッダー情報とTCPヘッダー情報、サーバー仮想化ソフトから収集したCPU使用率。これらの傾向や相関をモデル化 | 分析/可視化モジュールが30万円から、サーバー情報収集モジュールが15万円から、ネットワークパケット情報収集モジュールが15万円から |
前述した米Sprintの事例は、システム障害を事前に検知することを目的に、HP Service Health Analyzerを導入した例である。効果を調べるために試験的に導入した際に、いずれも30分前に障害の発生を予測したという。一方、国内金融機関の事例は、この金融機関と取り引きがあったNECが、障害発生時のログを受け取り、WebSAM Invariant Analyzerに入力した結果である。ログを機械的に処理するだけで、システム障害の原因を突き止めたという。
こうした“障害予兆検知ツール”が運用管理システムのベンダー各社から発売された背景には、クラウドあるいはサーバー仮想化環境の普及による情報システムの複雑化がある。ブラックボックス化によって、サーバーごとのリソース使用状況や、異なる性能監視データ同士の依存関係などが見えにくくなっているのである。