大手プロバイダーの多くは、自社の個人ユーザー向けに迷惑メール対策を提供している。設定はすべて各プロバイダーのWebサイトで行う。
最近増えてきた学習型フィルターの設定は簡単だ。例えば@nifty(下図)では、各ユーザーの専用ページにログインしてボタンを押すだけ。他のプロバイダーでもWebサイトから申し込みをした後に、やはりユーザーの専用ページで設定をする。いずれも迷惑メールを専用フォルダーに入れたり、プロバイダーに報告したりすることでフィルターを学習させ、判定精度を上げることが可能だ。
| 【メールを分析して育つ学習型フィルター】 |
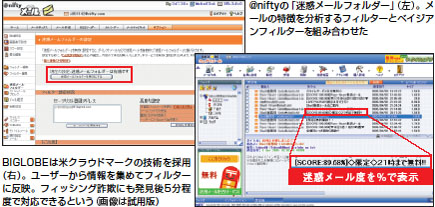 |
学習型フィルターの迷惑メール処理方法は、大きく分けて3つある。(1)サーバー上の特定フォルダーに振り分ける(Webサイトで迷惑メールの内容を確認可能)、(2)件名に特定の文字列を挿入する、(3)ヘッダー情報(※1)を追加する(各サービスの対応は左表参照)。(2)と(3)では、この情報を基にメールソフトのルールで振り分ける。(1)では迷惑メールの受信数が多い場合に、それらをパソコン上にダウンロードする手間が省ける。
| 【プロバイダーが提供する学習型フィルター(会員向け)】 | |
| プロバイダー | サービス |
| @nifty | 迷惑メールフォルダー |
| BIGLOBE | 迷惑メールブロックサービス |
| hi-ho | hi-ho迷惑メールフィルター |
| インターネットイニシアティブ | IIJmioセーフティーメールサービス |
「迷惑メール度」を判定
学習型フィルターで有名なのは「ベイジアンフィルター」だ。受け取ったメールを、ユーザーが迷惑/通常のメールの2通りに分類。これを繰り返すと2種類のサンプルを集めたデータベースができるので、単語ごとに各データベースにおける出現率を計算する。例えば「free」が含まれる確率を、迷惑メールでは80%、普通のメールでは20%だとした場合、「free」は“迷惑メール度”が高い単語となる。新しいメールが届いたら、本文中の単語の“迷惑メール度”を基に「メール全体が迷惑メールである可能性」を計算。一定のしきい値を超えたら迷惑メールと断定する。
| 【ベイジアンフィルターの仕組み】 |
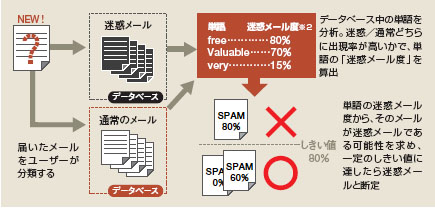 |



















































