紙の書類をパソコンにスキャナーで取り込むと、画像になる。この段階では、デジカメの写真と同じで、書類の文字はパソコン上ではテキストではないため、コピーも検索もできない。この「書類の画像」はPDFファイルにしても状況は同じ。文書に含まれる語句を検索したり、内容をワープロなどにコピーして活用することはできない。
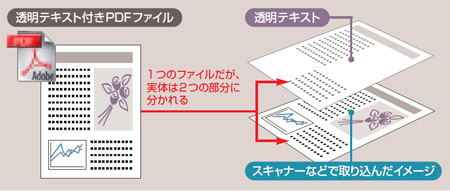
そこで、この画像の文字部分を読み取ってテキストに変換。そして、テキストを書類の画像に見えない形で重ね合わせて一体化する(図1)。これが「透明テキスト付きPDF」だ。このテキストは「透明テキスト」の名の通り、目には見えないしそのままでは印刷もできない。通常、目に見えていて印刷ができるのは、あくまで「書類の画像」だ。
ただし、テキストは、画像の文字部分に該当するテキストを重なる形で、書類の画像にほぼ忠実に配置されている。透明テキスト付きPDFファイルを検索すると、透明テキストが検索対象となる。透明テキストは、マウスで選択してコピーすることもできる。もっとも、OCRの読み取り能力は完ぺきではない。画面上では「活用」と書かれている部分が「乱用」などと誤認識され、「活用」でPDF ファイル検索しても、目当てのファイルがみつからない、といったこともある。
|
| 図1 透明テキスト付きPDFもファイルの扱いは普通のPDFファイルと同じ。アイコンも変わりはない。ただ、PDF化された画像に、テキスト情報が組み合わされて1つのPDFファイルになっている |



















































