Point
1. サーバー統合の過程でキャパシティ不足に陥った
2. NTクラスタリングで切り替えに失敗,RACで可用性を向上させた
3. ワームがもたらした被害をネットワークのトラブルと誤認
![]()
| ||
| ||
|

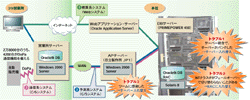
同社の自動販売機を管理する「HOWKS」は3つのシステムから成る。(1)自動販売機への製品積み込み状況などを管理する「精算系システム」,(2)自動販売機が販売状況をパケット送信する「通信系システム」,(3)上記2つからの収集データを基に,需要を予測する「予測系システム」――である。
今回,39の営業所に配置したサーバーの保守を効率化する目的で,それらを本社サーバーへ統合するプロジェクトを進めた。2003年6月に開始,2004年4月に予定通り終了できた。
1年半でキャパシティが限界
HOWKSは2000年に開発した,同社にとっては初めての基幹系オープンシステム。RDBMSにOracle8i(8.1.6)を採用,アプリケーションはPL/SQLによるストアド・プロシージャで実装した。2000年12月には関係ベンダーを集めて,「HOWKSを搭載できるスペック」という条件を示し,DBサーバー機の提案を募った。その結果,Windows NT Server 4.0を搭載した米IBMのIAサーバー「Netfinity 5600」の採用を決めた。
サーバーはクラスタ構成を採用。ハードウエアとミドルウエアに約1億円を投じた。HOWKSは2001年6月に稼働開始したが,システムの品質に問題があり,実質的な本稼働は2002年2月までずれ込んだ。初稼働開始から約1年半後,想定よりも早くNetfinityのキャパシティの限界に直面した。
高負荷で処理結果が異常に
Netfinity 5600は「当時の最上位機種」であり,同社としてはHOWKS以外でも活用したかった。そこで,売り上げ速報を出力するシステムを追加。ここまでは問題なかったが,2002年10月に,日報を出力するシステムを追加した際に不具合が生じた。
精算系,速報,日報の夜間バッチ処理を同時実行すると,負荷の高まりから,速報システムに不可解な処理結果が出力された。処理自体は正常終了するものの,出力結果がでたらめな数字になっていたのだ。日報システムを追加する以前には見られない現象であり,速報システムの処理を単体で実行すれば正常な結果が得られる。
この現象は毎晩続いた。困った清水氏らは日本オラクルにサポートを依頼。しかし原因は判明しなかった。やむなく速報システムを別のサーバーへ移行して問題を回避した。「無計画にシステムを追加してしまった」(北陸コカ・コーラボトリング 常務取締役 システム統括部長 兼 ヒスコム 代表取締役社長 清水淳正氏)と反省する。
データ量が見積もりを超えた
2002年12月,営業所で稼働している予測系システムを,本社のDBサーバー(Netfinity 5600)に統合する計画が立ち上がった。C/S型システムで構築したものの,営業所サーバーとのデータ同期やマシン保守の管理が難しいことが分かったからだ。ヒスコムの渡辺氏が事前テストとして18営業所のデータをDBサーバーへ統合して,バッチ処理を実行した。
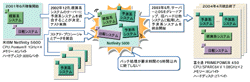
18営業所すべてのバッチを5時間で終わらせたいというヒスコムの考えに対して,ある大規模営業所のバッチだけで6時間もかかってしまった。これには清水氏以下,頭を抱えた。2000年12月にサーバー提案を受けたときには,予測系システムも統合できるスペックだったはずだ(次ページの図2[拡大表示])。その提案からまだ2年。
しかしその2年間に,比較的容量の大きいデータを扱う日報システムが追加されていた。予測系システムのデータも予想を上回るペースで増えていた。こうした状況から渡辺氏は,バッチの処理時間が長いのは,ディスクI/OおよびCPUのパワー不足が原因と考えた。とにかく,需要の予測処理が翌朝に間に合わなければ,同社のセールス業務に多大な影響を与える。処理時間は譲れない条件だった。
そこで,代替のサーバーの検討に入った。その際,Windows系OSを採用することは避けた。当時は,先に説明した速報システムのトラブルが未解決なままだったためだ。そうした中,富士通が提案を持ちかけてきた。予測系のすべてのデータで5時間以内にバッチ処理が終わるかどうかを,Solarisサーバー「PRIMEPOWER 450」とOracle9i DB,および RAC(Real Application Clusters)の組み合わせで富士通が検証。その結果,5時間以内に無事終了できた。サーバーのハード費用だけで約1億円したが,採用を決めた。



















































