![]()
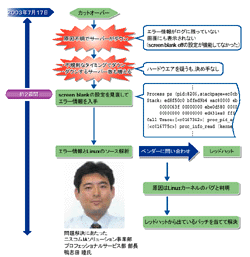 |
| 図1●Linuxのバグによるトラブルでサーバーがダウン サーバー・ダウンが不規則に発生し,原因究明に手間取った。エラー情報を入手した後,エラー情報やソースを解析。OSベンダーのレッドハットへの問い合わせから,原因を特定できた。結果,パッチの適用によって問題は解決した |
これまでSolarisなどUNIXサーバーで構築していたシステムを,ほぼ全面的にLinuxで再構築したものだ。同社 技術開発部 リーダー 千葉正彦氏は,「メールが止まればユーザーからの反響が大きい。ノンストップが必須。我々にとって基幹システムであり,経験が浅いLinuxの採用は大きなチャレンジだった」と振り返る。
ISP業界は今,「安定したサービスを“安く”提供しなければ生き残れない」(同社 ネットワーク管理部 リーダー 安達伸哉氏)。そのため今回,コストにこだわった。IAサーバーとオープンソース・ソフトの組み合わせを選択。効果は評価中だが,試算ではUNIXサーバーで構築する場合と比べて「初期コストで1/2から1/3。ランニング・コストを含めたトータルでも1/3」になる見込みだ。
ただ,コストを追求したとしても「無謀なことはできない」(千葉氏)。オープンソース・ソフトでは,自分たちだけで手におえない場合もあるだろう,と感じていた。専門家の強力なサポートが必要だった。コストと安全性の兼ね合いから,製品はサポート・サービスがあるRed Hat Linux Advanced Server(AS)や商用版Sendmailを,開発はLinuxなどオープンソース・ソフト関連の技術を持つSIベンダーとしてニスコムを選んだ。
原因不明のダウンが頻発
こうした専門家のサポートを選択したことが,カットオーバー直後に功を奏す結果となった。
カットオーバーして数日後のある日,原因不明のサーバー・ダウンが発生した(図1[拡大表示])。ダウンの原因となるエラー情報は,画面にもログにも残っていなかった。ただ,サーバーを再起動すれば動いた。
対処にあたった鴨志田睦氏(ニスコムのIAソリューション事業部 プロフェッショナルサービス部 部長)は「最初はハードウエア障害を疑った」。システム・テストの際にハードウエアの初期不良が起きていたのと似た症状だったためだ。当面は,再起動だけで様子を見ることにした。
しかし状況は悪化。ダウンするサーバーは増えていった。週に3台程度ダウンした。特定のサーバーではなく,どのサーバーにおいても発生。サーバーがダウンする時間帯もばらばら。利用者の少ない土曜日の午前中にも発生する。再現できないエラーであり,ひたすらサーバーを再起動するほかなかった。徐々に「関係者から笑顔が消えていった」(千葉氏)。
Linuxカーネルのバグを究明
状況が好転したのは,エラー情報が取れた時点からだった。実はエラー情報が画面に表示されなかったのは,Linuxのスクリーン・セーバー機能に当たる「screen blank」の設定ミスだった。オフの設定にしていたはずが,実際には正しく設定されていなかった。
鴨志田氏は早速,エラー情報の解析に取り掛かった。すぐにカーネルのエラーでダウンしていることが分かった。しかしそれは意外だった。システム・テストではダウンが発生していなかったため,カーネルのエラーは疑っていなかった。
エラー情報から,トラブル原因のおおまかな見当はついた。当時Linuxのカーネル2.4で,よく問題が取りざたされていた関数が,“カーネル・パニック”を引き起こしていたからだ。鴨志田氏はLinuxのソースを解析するとともに,想定したトラブル原因をOSベンダーのレッドハットにメールで送信して回答を求めた。
すぐに返信がきた。結果は想定した通り,プロセス情報を表示する「psコマンド」のバグだった。実は,システムを定期観測するために全サーバーに対してpsコマンドを巡回起動させていた。テスト時には動作させていなかったもので,カットオーバー後に導入した。だからテスト時には発生しなかった。安定稼働のための方策が,皮肉にもサーバー・ダウンを引き起こしていた。
またこのpsコマンドのバグは,ある条件がそろったタイミングだけ発生するものであった。そのため,不規則に発生しているように見えたわけだ。
レッドハットからこのバグを修正したパッチが運良く提供されていた。「障害原因は間違いなく同バグによるもの」とレッドハットからお墨付をもらえたことから,パッチを適用して解決した。完全解決までカットオーバーから約2週間だった。



















































