![]()
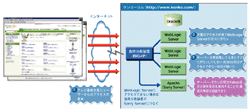 |
| 図1●アクセスが集中してWeb/APサーバーが次々にダウン 2003年3月2日の20時過ぎ,テレビ番組を見たユーザーからの大量アクセスが来てWeb/APサーバーがダウン。再起動してもすぐにダウンしてしまい,約30分間はアクセスできない状態が続いた。アクセス・ログを分析した結果では,通常の6倍以上のユーザーがアクセスしていた |
TV番組を見てアクセスが殺到
大量のアクセスが来たのは,あるテレビ番組で,花粉症に効果があるとして「シジュウム茶」が紹介されたのが原因。当時は「シジュウム茶」を販売しているECサイトがほとんどなく,Googleなどの検索サイトで調べると,同サイトがトップまたは上位に表示された。必然的にアクセスが集中することになる。
そのテレビ番組の放映は20時から。「放送開始数分後にはサーバーがパンク状態になっていた」(丸氏)。携帯電話にアラートのメールが届き,Webブラウザでアクセスしてみると反応がない。メンテナンス回線を使ってサーバーに接続してみたものの,サーバーがハングアップ状態でなかなかログインできなかった。
ログインができても状況は改善できなかった。APサーバーのWebLogic Serverが再起動できない。仕方なくOSごと再起動するが,アクセスの集中はやまず,またすぐにダウンするという繰り返し。正常に処理できるようになったのは20時30分過ぎだった。
約30分間はアクセス不能の状態が続いたが,Web/APサーバーがダウンしている間は負荷分散装置が「Sorry Server」にアクセスをつなぐことで最悪の事態は回避できた。Sorry Serverではサイトが混雑していることを知らせ,同社のYahoo支店と楽天支店を案内する。自社サイトはダウンしたが,この2つの支店を含めて過去最高となる約2000万円を売り上げた。
ただ,損害がまったくなかったわけではない。Yahoo支店や楽天支店は,売上高に応じて月額料金が決まる。これらの支店にユーザーを誘導することで購入の機会損失は防げたが,自社サイトで販売できなかった分だけ損をしたことになる。今後このような事態を避けるためにも,大幅なシステム強化が必要となった。
サーバー増強でキャパを2倍に
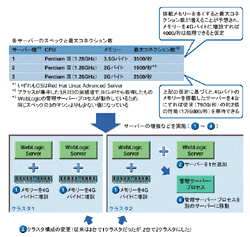 |
| 図2●サーバーの増強などを実施して従来の約2倍の処理性能を確保 サイト全体の処理能力を高めるため,(1)Web/APサーバーのメモリーを4Gバイトに増設,(2)サーバー機を1台追加,(3)クラスタ構成の変更,(4)管理サーバー・プロセスを別のサーバーに移動――という対策を実施した |
Webサーバーのアクセス・ログを調査した結果,3月2日20時~21時の訪問者数は約1万2000。通常時が2000前後であることを考えると,約6倍以上のアクセスが来ていたことになる。既存の約6倍の処理性能を目標に,システムを強化していくことにした。
まず実施したのが,サーバーの増強だ(図2[拡大表示])。負荷分散装置の管理画面で最大コネクション数を調べてみると,サーバーが搭載するメモリー量と比例関係になっていることが分かった。それぞれの内訳は,(1)3.5Gバイトを搭載したマシンで最大3500コネクション/秒,(2)同2Gバイトで1900コネクション/秒,(3)同2Gバイトで2500コネクション/秒――である。同じメモリー量にもかかわらず(2)と(3)に差があるのは,(2)がWebLogic Serverのクラスタを管理する「管理サーバー・プロセス」を搭載しているためだ。
大雑把ではあるが,メモリーが4Gバイトあれば,1台で最大4000コネクション/秒は処理できると想定し,すべてのサーバーのメモリーを4Gバイトに増設した。サーバー機も1台追加し,合計で1万6000コネクション/秒まで処理できる体制にした。
同時にWebLogic Serverのクラスタ構成も見直した。従来は3台で1つのクラスタを構成していたが,1台追加して単純に4台で1つのクラスタにしたのでは無駄が多い。アットマーク・アイティ(@IT)に出ていた記事「事例に学ぶWebシステム開発のワンポイント(3)」(http://www.atmarkit.co.jp/fjava/rensai2/webopt03/webopt03.html)を参考にし,2台ずつで2つのクラスタにした方がトータルの処理量は多くなると判断した。
管理サーバー・プロセスも別のサーバーに移した。メモリーの消費量を減らす目的もあるが,実はこの管理サーバー・プロセスが3月2日のサーバー・ダウン時に大きな問題となった。クラスタ構成にしている場合,管理サーバー・プロセスがダウンしていると,サーバーが起動できないのである。3月2日のダウン時も,まず管理サーバー・プロセスを起動してから他のWebLogic Serverを起動するという手順をとらなければならなかった。そのため,本来はユーザーからのアクセスを受けない別サーバーで管理サーバー・プロセスを動かすのが一般的になっている。



















































