![]()
文字処理の主役,Webブラウザの能力
以上から考えると,文字化けを回避するには,Webブラウザがなんとかするしかないといえる。ここから先は,WebブラウザがどのようにしてWebサーバーから受信したデータの文字コードを判定するのかという点について,調べていこう。ただ,Webブラウザの種類によって挙動が違うので,ここではパソコン用2大Webブラウザ,Internet Explorer(インターネットエクスプローラ)とNetscape Navigator(ネットスケープナビゲータ)を対象に話を絞って進めていく。
|
|
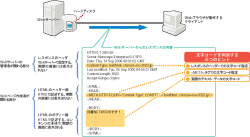
図3 Webサーバーからのレスポンスには,文字コードを判別するためのヒントが入っている レスポンスの中にある情報に基づいて,Webブラウザは文字コードを判別している。その情報は大きく分けると三つ。(1)HTTPレスポンスのヘッダーの文字コード指定,(2)HTMLデータ中にある<META>タグを使った文字コード指定,(3) Webページのテキスト・データ――である。(1)は通常,Webサーバーの管理者が設定する。(2),(3)は,Webページ作成者が決める。 |
三つの判別情報とは
Webブラウザが受信データの文字コードを判断する材料は,Webサーバーからのレスポンスしかない。レスポンスの内容は,ヘッダー部分とHTMLデータに分かれる。Webブラウザは,それぞれの部分に入っている情報を,文字コードの判断材料にしている。その判断材料は一つではなく,三つある(図3[拡大表示])。一つは前述のヘッダー部分に挿入されている情報である。例えば,「Content-Type: text/html; charset=iso-2022-jp」などとヘッダー部分に記述されていれば,受信したHTMLデータはJISコードであると判断できる。この情報は,通常Webサーバーの管理者があらかじめ設定しておくことになっている。なお,このヘッダー情報はオプション扱いになっているので,Webサーバーによってはこの情報がないレスポンスが返ってくることがある。
もう一つは,実際のHTMLデータの中にある。HTMLデータは,タグと呼ぶ「 < 」と「 > 」で囲んだコマンドを含むテキストで,これらのコマンドにより文字の配置やリンク先などを指示している。このコマンドのなかには,HTMLデータを記述したテキスト文字の属性を指定できるものがある。それが<META>(メタ)タグだ。例えば,「<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=iso-2022-jp">」のように記述する。ただし,この<META>タグがなくてもHTMLデータとしては問題がない。このため,<META>タグがないWebページを公開しているWebサイトはインターネット上にかなりある。
さらにもう一つ,判断材料がある。HTMLデータ自身である。HTMLデータ自体は,単なるビット列である。このビット列から文字コードを推測するのである。確実に文字コードを特定することは難しいが,ある程度の推測は可能である。
まとめると,Webサーバーが送り返してきたレスポンスを見て,Webブラウザはその中にあるHTMLデータの文字コードを判断する。その判断材料となるのは,(1)レスポンスのヘッダー情報,(2)HTMLデータ中の<META>タグ情報,(3)HTMLデータ自身――の三つである。



















































