![]()
| ||
|
GAは事象に対応する処理に入力するデータの組を「遺伝子」で表し,その適合度によって事象に対して適切な状態を生み出すアルゴリズムだ。
カオスは簡単に言ってしまえば,「結果を見るとランダム(完全な無秩序状態)と同じで予測不可能だが,その事象の発生には規則が内在する現象」のこと。規則が内在しなければランダムになる。その内在する現象を取り出せれば,一見予測不可能な現象であっても短期的には予測可能になる。
ただ対象とする現象が複雑であるがゆえに,実用化はそう簡単ではない。GAは部分的に使われ始めている一方で,カオスはまだまだ研究途上といった段階にある。
| GA:最適化手法としてほぼ確立 |
親から子へ,子から孫へ,生物は世代を経るごとに前の世代の性質を残しつつ変化している。環境への適応度が高い遺伝情報が優先されることで,生物は進化してきた。GAはこのような生物の遺伝と進化になぞらえて,遺伝子となるデータの選択淘汰を繰り返す計算手法である。
GAは1975年,J. H. Holland氏によって提唱され,スケジューリングや組み合わせ最適化問題に適用された。現在では,列車の運行ダイヤの編成などで使われている。また,「ファジィのルールを修正するなど,チューニング手法として使っている」(大阪府立大学総合科学部数理・情報科学科の馬野元秀教授)など,部分的に用いることも多い。
適合する個体を選択し淘汰する
GAで扱うデータ構造は生物の遺伝子を模擬している。操作の対象となる記号や数値の列を遺伝子と見立てる。その遺伝子が目的となる環境にどれくらい適しているか(適合度)を判定し,状況に応じて遺伝子を変えていく。
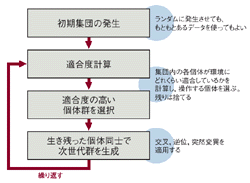
したがってGAの操作は大きく四つの段階から成る(図1[拡大表示])。まず操作の前に,問題を解くためのパラメータを遺伝子で表現する。遺伝子を形成したら,第1段階として操作対象となる初期集団を発生させる。初期集団の数は世代当たりの計算量に影響するため,処理能力に応じた数にする。第2段階で集団内の各個体の適合度を計算する。次の第3段階で,適合度の計算結果から操作する個体を選択する。ここでは,適合度が高いものを残して低いものは捨てる(自然淘汰に相当)。第4段階は残った個体から次世代を構成する新たな集団を作り出す作業だ。そして第2段階に戻り何度もこの作業を繰り返す。
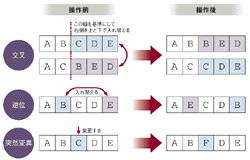
このうち第4段階における遺伝子に対する操作は,次世代群の形成に大きくかかわる部分である。具体的な操作は交叉,逆位,突然変異の三つ(図2[拡大表示])。交叉は二つの遺伝子のある部分から先のデータを丸ごと交換する操作。生命の交配に相当する。逆位は一つの遺伝子のうち,遺伝子内部のある二つのデータを交換する。突然変異は遺伝子の一部のデータをランダムに変える操作である。
説明できない部分も残る
この探索方法で最適解に至る過程は,山登りにたとえて考えると分かりやすい。高さが異なる複数の山のなかで一番高い山に登る場合,単純に考えれば出発点から周囲を見わたして現在地よりも高い場所を探して登っていけばよい。この方法を最急勾配法という*1。
ところがこの方法では,出発点近くの山の頂上に登ることはできても,それよりも高い山の存在は知り得ない。つまり探索範囲の中にある,最適解ではない解(局所解)に収束してしまう。一方GAは,初期集団に交叉や逆位を適用するため,山を並列に登っていくイメージである。時には突然変異によって,それまでとは別の山に登ることもある。
ただしGAをうまく適用する方法は確立していない。説明できない部分があるためだ。例えば,遺伝子の操作と結果の関係。複数ある遺伝子操作をそれぞれどれくらいの確率で起こすべきか,これらの操作が本当に良い結果をもたらすのかなどは分かっていない。また,問題を解くためにどう遺伝子を表現するかが難しい。収束が比較的遅いこともあり,GAで良い結果を出すにはノウハウが必要になる。



















































