受信メールを基に学習する
| ||
|
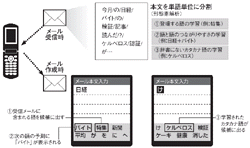
三つ目のアプローチは,2004年にオムロンソフトウェアが「Advanced Wnn V2」に盛り込んだ機能(図5[拡大表示])。ユーザーが受信したメールの中身を解析/学習することで,そのユーザーが過去に入力したことのない語も予測候補に挙げる。
Advanced Wnn V2は,ユーザーに届いたメールを形態素解析して単語単位に分解する。解析の結果を基に,3種類の学習をする。(1)そのメールに登場する語,(2)語と語のつながりやすさ,(3)辞書に未登録のカタカナ語,である。
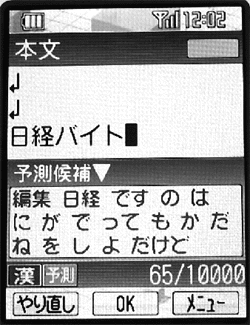
(1)の語は,たとえ一般的にはあまり使われない言葉であっても,文字入力時に予測候補の上位に出す。(2)の情報は,文字確定後の予測の際に利用する。例えば「日経バイト」という文字を含むメールを受信したとき。「日経」と「バイト」がつながりやすいことを学習する。メール作成時に「日経」と入力すると,予測候補の最上位に「バイト」が表示される。
(3)は,辞書に登録されていないことの多いカタカナの固有名詞や専門用語の入力を容易にするものだ。前後のひらがなや漢字など異なる文字種の文字を区切りとしてカタカナ語を学習する。
2004年11月末に発売された「W22SA」に,この機能を搭載した(画面2)。受信したメールへの返信を書くときに,この学習機能が働く。返信時は,受信メールと同じ話題を扱う可能性が高いためだ。
次の決定打は見えていない
もちろん,現状の文字入力機能は完全ではない。しかし,今のところ決定打となるような新たな手法は見えていない。
明らかな課題は,大きく三つある。まず,きめ細かな予測が不十分なこと。固定的な条件に基づいて予測候補を切り替えるだけでは,画一的な予測しかできない。メールを送る相手が同じでも,使われる言葉が同じとは限らない。
この問題に対処するには,もっと柔軟に予測候補を切り替える必要がある。そのためには「その人が入力中の語句をリアルタイムに解析して,動的に予測候補を変えるといった処理が必要」(オムロンソフトウェアの山野氏)。限られたCPU性能やメモリー容量の中でどう対処するか,研究が進められている。
二つ目は,予測の単位が単語や文節単位に限られていることだ。これでは,一度に短い単位でしか入力できない。「かな漢字変換における連文節変換のように,複数の文節を一度に予測したい」(ジャストシステムの丸山氏)。ただし複数文節を一度に予測しようとすると,候補の数が膨大になる。これを抑えながら,適切な候補を提示するのは難しい。
三つ目は,予測だけでなくかな漢字変換機能にも共通する課題である。辞書に登録済みの単語しか候補に出せないという根本的なものだ。
日本語としてあまり一般的でない漢字の入力時に問題になる。JIS第二水準の漢字には珍しいものが少なくない。こうした漢字は携帯電話用にサイズを縮小した辞書には入っていないことがある。これでは,読みを入れても予測や変換の候補に出てこない。「パソコン向けのかな漢字変換ソフトは,部首名や画数を使って漢字入力する機能を備えている。それと同じような入力方式を実現できないか考えている」(バックス国際言語処理システム部の加藤昌範主任)。



















































