![]() データベース。かつて1980年代から1990年代にかけて,パソコン3種の神器と言えばワープロ,表計算ソフト,データベースと呼ばれていた。ワープロならばジャストシステムの「一太郎」や管理工学研究所の「松」であり,表計算ソフトはロータスの「1-2-3」かマイクロソフトの「Multiplan」。そしてデータベースといえば日本アシュトン・テイトの「dBASE III」や管理工学研究所の「桐」が代表例だった。
データベース。かつて1980年代から1990年代にかけて,パソコン3種の神器と言えばワープロ,表計算ソフト,データベースと呼ばれていた。ワープロならばジャストシステムの「一太郎」や管理工学研究所の「松」であり,表計算ソフトはロータスの「1-2-3」かマイクロソフトの「Multiplan」。そしてデータベースといえば日本アシュトン・テイトの「dBASE III」や管理工学研究所の「桐」が代表例だった。
WindowsがOSの標準としての地位を確立してからも,ワープロや表計算ソフトは多くのユーザーに使われている。半面データベースは元気がない。マイクロソフトのオフィス・スイートにある「Access」が健闘しているものの,もはや必須のツールという感覚はない。
だがデータベースがなくなってしまったわけではもちろんない。見えないところでデータベースは活躍している。どんなアプリケーション・ソフトであっても,データを取り扱うものである以上,何らかのデータの入出力は発生する。そのデータを貯めておくものであれば,データベースを備えているのだ。
代表的な例が年賀状ソフトだ。誰もこれを「データベース・ソフト」とは呼ばない。しかしその送付先管理はデータベースそのものだ。ある特定の機能に特化したアプリケーションの方が使いやすくできる。そしてそのアプリケーションの実装にデータベースが使われているのだ。
データの“設計”が必要
| ||
| ||
| ||
| ||
| ||
| ||
|

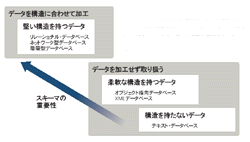


役割を終えたわけではないのに,データベース・ソフトが衰退したように見える理由。それはデータベースがあくまでも「システム構築の一環で使われるもの」で,システムを実際に構築するにはいくつものハードルがあるからだ(図1[拡大表示])。
データベースを構築するには,どのようなデータをどのような形で格納し,どうやって取り出すのかを検討しなければならない。「データ設計」と呼ばれるステップだ。例えばAccessなら,データの容器として「テーブル」を定義する。このときに,同じ情報が複数の場所に存在しないように配慮する。そうでないと,ある部分を更新したときに重複する別の箇所が正しく更新されず,データに矛盾が発生してしまう可能性があるからだ。
これを名刺管理の例で考えてみよう。名刺一枚一枚に住所が入っている単純な構造を選択すると,ある会社が事業所を移転したときに,個々の名刺ごとにすべてのデータを変更しなければならない。修正が多く発生して間違える元になりかねない。だが事業所移転など滅多にあることではないし,その担当者が別の事業所に移動することなどもよくあるから,個別に管理すべきという考え方もある。こういったトレードオフを見極めなければならない。
データ設計だけではまだ使えない。アプリケーション・ソフトとして使えるようにするには,ユーザー・インタフェースやデータベースを操作するロジックを作り上げなければならない。こういった作業は決して単純ではない。
さらに無事システムが完成したとしても,まだ落とし穴がある。データの運用管理である。この体制をうまく作っておかないと,せっかくのデータベースが古いものになって使えなくなってしまうからだ。データの追加・更新があったときに,適切にデータベースにそれを反映する体制作りが必要である。
こういった事情から,「個人がデータを管理するのに,まず使うのはExcel」(管理工学研究所 販売推進の武田道朗氏)。実際,エンドユーザーが作業する場合,Excelにはいろいろと便利な面がある。まずわずらわしいデータ設計は必要ない。それにExcelの場合,データの列の意味が固定的でない。データベースの場合,設計時に与えた意味にしたがってデータを入れなければならない。ここを柔軟に変えられるのはExcelならではだ。表でデータを考えるというのは,人間にとって自然だ。
Excelで管理が難しくなるのは,データ量がある程度以上になったり,データの構造がややこしくなってきたときだろう。そこに限界を感じて初めて,データベース・ソフトに手を出す。その意味で,現在エンドユーザーが求めるデータベース像は,データベース設計が不要でデータを格納できるものだ。これは今までの「データベース管理システム」とは相容れない考え方である。だが,ここにデータベースの明日を探るヒントがあるのではないだろうか。
多岐にわたり存在するデータベース
ここで改めてデータベースとは何かについて,考えてみる。基本的にはデータの基地(ベース)であり,定型不定形に関わらずデータを蓄えたものがデータベースで,それを管理するのがDBMS(データベース管理システム)だ。
データが集積してさえいればデータベースと呼べるので,さまざまなデータベース製品が提案されてきた。データベースの分類方法はいくつかあるが,まず考えられるのが動作モデルである。DBMSの実装方法による分類で,「デスクトップ・データベース」などと呼ぶ場合に使っている。
もう一つがデータモデルによる分類だ(図2[拡大表示])。例えば「リレーショナル・データベース(RDB)」はそのDBMSにおけるデータモデルを表現した言葉である。この分類ではほかに,ネットワーク・データベースや階層型データベースなどがある。
微妙な位置に存在するのが「XMLデータベース」である。これはデータに格納するデータの形式を表現している。データには構造はあるものの,データの順番に意味がないという点で,柔軟なデータ構造と言える。
テキストデータのまま格納するテキスト・データベースもこれと同じ意味を持つ。ただこれらについては,不定型なデータを格納するという意味において,データモデルの一種ととらえることもできる。
以下,整理の意味でこれらの分類をもう少し詳細にしていこう。
データベースらしいC/Sモデル
現在,「データベース」と陽に認識されるものは,ほとんどクライアント-サーバー(C/S)・モデルで動作するものである。クライアントが発行するデータ要求(クエリー)に対し,検索結果だけを返すものだ(図3[拡大表示])。これに対し,クライアント・マシンだけで動作するものがデスクトップ・データベースである。ただし1台だけでは不都合な場面も多いので,ネットワークを通じて同じファイルを共有して利用できることが多い。このタイプを「ファイル共有型」と呼ぶ。ファイル共有型の場合,一般にデータ量が増えるとネットワークを流れるデータ量が多くなってしまう。規模が大きくなるほど不利である。しかし小規模であれば,データベース・エンジンが軽くできているぶん高速に動作することもある。
C/Sモデルの場合,クエリーを発行するための仕組みが必要である。通常ここは,SQL(Structured Query Language)を使う。ある意味,SQLという標準インタフェースを確立したことが,現在のデータベース市場を生み出したと言っても過言ではない。
SQLでクエリーを共通化することにより,データベースの移行性や保守性が高くなる。また開発者のスキルという点でも,スキルを維持しやすい。SQLは後述するように,もともとRDBのために作られた言語である。“ポスト・リレーショナル”と呼ばれながらなかなか成功した新しいアーキテクチャのデータベースが出てこないのも,このSQLという存在があるからかもしれない。
データモデルの違いに特徴が出る
だが多くの場合,データベースの分類といえば,データモデルに従う。データモデルとは,データをいかに表現するかを定めたものだ。
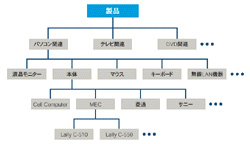
初期のデータベースは階層構造でデータを管理していた(図4[拡大表示])。データの関連を階層によって表現したのだ。一つのノードが一つのデータの固まりを表す。したがって論理的には一種の木構造のデータとなる。ただそれぞれの階層の関係が固定的で柔軟性に欠ける。特に最初のころのデータベースは,ファイル・システムではなく直接ディスクに対し読み書きをしていたため,構造を変えることがすなわちデータの配置すべてを書き換えることになっていた。このため簡単にはデータ構造を変えられなかった。さらに論理的な問題として,ある階層に存在するデータはそれぞれすべてのノードに配置しなければならないという欠点もある。つまりデータの属性が変わった場合など,その内容をすべてのノードに反映させなければならない。
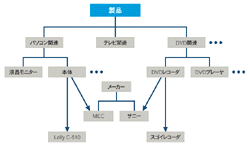
階層型にもっと柔軟なデータ表現を組み込んだのがネットワーク型である(図5[拡大表示])。階層型では個別のデータ要素の関係を親子関係でしか表現できなかったが,ネットワーク型では参照関係でも表現が可能になる。従って,複数のエントリで参照している項目を1カ所にまとめ,重複をなくするデータ表現が可能だ。ネットワーク型はCODASYL型とも呼ばれ,COBOLで多く用いられたデータベースである。後述するリレーショナル・モデルが登場してからも,しばらくはメインフレーム用データベースの中心的存在だった。
だがネットワーク型にしても,データ構造の変更に対して柔軟に対処しにくい。リンク関係という物理的な実装に近いもので,データの関係を定義しているからだ。
データの関連に柔軟性を持たせる
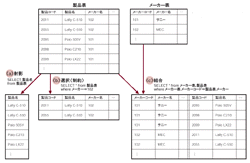
そこに登場したのがRDBである。RDBは1970年にE. F. Codd氏が提案したリレーショナル・モデルに基づいている。すべてのデータを2次元の表という,人間にとって直感的で分かりやすい形で表現する(図6[拡大表示])。
それぞれの表は基本的に独立した一群のデータであり,複数の表を結びつけるのはデータの値である。ここがネットワーク型と根本的に違うところだ。つまりデータベースの構造に大幅な影響を与えずに,データ構造を変更できる。
具体的には関係演算と集合演算を組み合わせることによって,ネットワーク型と同じデータ構造を表現する(図7[拡大表示])。ただし結合はそれなりに重い処理である。このため結合の対象とするテーブルはあらかじめ検索しておいて,レコード数を絞り込んでおくといった工夫が必要である。
現在のデータベースはほとんど,基盤はRDBの技術を使っている。メインフレームではしばらくネットワーク型データベースが主役だったが,最近はオープンな技術を使って構築する事例が圧倒的である。このようなケースで使われるデータベースは,ほとんどRDBだ。



















































