| ||
|
メールを分類する二つの技術
スパムメールのフィルタリングには,大きく二つの情報を使う。一つがメールのヘッダー情報。送信元や件名などである。単純なフィルタリング・ソフトは,この情報だけを利用しているものが多い。例えば,スパム送信者として有名な送信元をリスト化しておく。フィルタリング時に,そこから送られてきたメールをスパムと判断する。件名に特定の語句が含まれているメールをスパムとすることも可能である。
ただしこれだけでは,未知の送信者や件名を持つメールはブロックできない。そこで使われる情報が,メールの本文である。本文のテキスト情報を解析して,それがスパムであるかどうかを判断する。本記事で取り上げた7製品は,すべてこの機能を持っている。
メールの本文を解析する手法として最も一般的なのが,ベイズ分類と呼ばれる手法である。どのようなメールがスパムであり,どのようなメールが正当なメールかという情報をあらかじめ用意しておく。送られたメールに対して,どちらの可能性が高いかを解析して結果を決める。Eudora,Norton AntiSpam,McAfee SpamKiller,Mozilla,POPFileの5製品がこの手法を採用している。
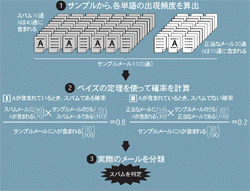
例えば,Aという単語が含まれるときそのメールがスパムであるか,そうでないかを判断する(図A[拡大表示])。まず,スパムメール,正当なメール両方を含むサンプルメールを用意する。それを解析して,各単語の出現頻度を算出する。次にベイズの定理を利用して,Aが含まれるときスパムである確率と,そうでない確率を導き出す。ベイズの定理とは,英国の数学者Thomas Bayesが発見したものである。確率を導き出すための数式として広く知られている。
実際には,複数の単語の組み合わせなどもっと複雑な情報を利用して解析する。また,使われる情報は必ずしも単語の出現頻度だけとは限らない。メールの構造など,単語以外の情報を使うこともできる。最終的にスパムである確率が一定値を超えたらスパムと判定する。
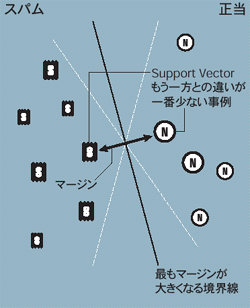
これに対して,Outlookが使っているのがSupport Vector Machine(SVM)と呼ばれる手法である(図B[拡大表示])。まずメールから抽出した特徴量から,一つのメールをベクトルで表現する。そしてすべてのメールをベクトル空間上に配置する。ベクトル空間においてスパムメールで構成された空間を切り出すのに使われるのがSVMである。それぞれに属する事例のうち,もう一方との違いが一番少ない事例間の距離(マージン)が最大になるように境界線を引く。
ちなみにウイルスバスターは,このどちらの手法も使っていない。経験則によって作られた判定ルールを適用することにより,フィルタリングしている。例えばある単語が入っていたら何ポイント,といったルールを用意しておき,総合ポイントが一定以上のものをスパムと判断する。「デフォルトで2000のルールを備えている」(トレンドマイクロの濱田氏)。



















































