| 日本語メールへの対応は今一歩 |
ここまでのテストは,すべて日経バイトに実際に届いたメールを使って実施した。スパムメールの実情には即しているが,テストとしてみると不足があった。一つは,英文の正当なメールが少ないこと。実際に届いた英文メールはほとんどがスパムであるため,英文の正当なメールを正しく判定できるか判断できない。
もう一つは,日本語のメール自体が少ないことである。コンピュータ系のプレスリリースがほとんどで,それ以外の正当なメールや日本語のスパムメールがどの程度判定できているかを測定できない。
| ||
| ||
|

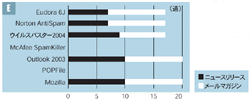
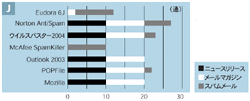
このため,英語と日本語の両方で,判定が難しいメールを自作してそれぞれのソフトに読み込ませてみた。スパムと区別が付きにくいメールの代表はプレスリリースとメールマガジンである。両方とも宣伝的な内容やURL を内容に含んでいるからだ。このため,英語と日本語のプレスリリースとメールマガジンのサンプルを10 通ずつ収集した(表2[拡大表示])。さらに日本語は,スパムメールのサンプルも1 0 通作成した。
英語に関しては,正しく判定できたものとそうでないものがはっきりと分かれた(図6[拡大表示])。一つも正当なメールと判定できなかったのが,POPFile とMcAfeeSpamKiller である。このうちPOPFileの結果が芳しくなかったのは,英語の正当なメールをほとんど学習させていなかったためだろう。McAfee SpamKillerは,デフォルトの状態から正当なメールを誤判定する確率が若干高かった。この傾向がこのテストでも現れたと思われる。
一方日本語の判定性能を見ると,正当なメールとスパムメールの両方をすべて正しく判定できた製品はなかった(図7[拡大表示])。どちらもそれなりに正しい結果を出せたのは,Norton AntiSpam ,ウイルスバスター,POPFile の3 製品。あとはほとんどスパムと判定したり,その逆の結果となるものばかりだった。たとえばOutlook やMozilla は,スパムメールをスパムと判断できたものは一つもなかった。
日本語のメールに対してそれなりの判定ができた3 製品は,どれも日本語独自の処理を導入しているものである。Nor-ton AntiSpam は,「日本語の文章を適切な単位に区切る技術を導入している」(シマンテックコンシューマ・マーケティング部プロダクトマーケティングマネージャの田上利博氏)。さらに日本のエンジニアが日本語のスパムメール固有の特徴を集め,フィルタリング・ルールに反映しているという。同じく日本語を文節に区切る技術を導入しているのがPOPFileである。「KAKASI 」というフリーの形態 素解析システムを利用している。
ウイルスバスターは,現時点では日本語のスパムメールに特有の判定ルールを用意し,フィルタリングに利用している。文節を区切るための技術は導入していないが「より精度を上げるために,今後形態素解析の導入も考えている」(トレンドマイクロマーケティング本部プロダクトマーケティング部プロダクトマネージャーの濱田茂氏)。
日本語向けに特別な処理をしていない製品のいくつかは,将来的な対応を予定している。例えばマイクロソフトは「Exchange Server には3 月に導入する。Outlook もその後対応予定」(マイクロソフトインフォメーションワーカービジネス本部オフィス製品部の井上智裕シニアプロダクトマネージャ)。Eudora にも,同様の計画があるという。
意味を判断できていない
最後に,さらに判定しにくいと思われるメール2 通を作成して読み込ませてみた。スパムメールを引用した警告メールである。以下のようなメールが出回っているので注意するべしという旨の情報システム部からの警告文のあとに,スパムメールの文章を引用した。
どのソフトも,引用したスパムメール単体のものとまったく同じ判断を示した。ここから,判定に利用しているのは単語の出現頻度などの情報のみであることが分かる。その意味については,どのソフトも解析できていない。
ここまで踏み込もうとすれば,形態素解析のみならず構文解析や意味解析など高度な自然言語処理技術を適用する必要がある。ただそこまでの手間をかけてどれだけ判定率が向上するのかは見えない。複雑な処理をすることによる副作用も起こるだろう。処理速度と必要性のトレードオフを見極める必要がある。



















































