スパム・フィルタリングのソフトには,ユーザーによる学習を前提としているものが多い。ユーザーによって,スパムと判断する基準が違うためだ。
実際に学習がどの程度有効に働くかを調べるため,一定量のメールを学習させて,それによって判定率がどの程度変わるかを調べた。
学習させたメールには,どのソフトも正しく判定できなかった40通のスパムメールのうちから30通を選んだ。学習させるメールに違いがあっては正当な評価ができないためである。選んだ30通がスパムであることをソフトに教え,次に同じ598通のメールを再度読み込ませるという方法を採った。
ただしこれだけの学習量では,デフォルト状態で何のフィルタリングもしないPOPFileとMozillaには不足である。そこでこの二つのソフトには,他のどのソフトもスパムと判定できた30通と,正当なメールと判断できた30通をあらかじめ学習させてから同じテストを実施した。当然ながら,学習機能を持たないOutlookとウイルスバスターは対象外とした。
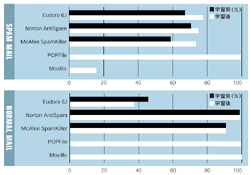 |
| 図5●学習による判定率の変化 どのソフトも判断を誤った30通のスパムメールを学習させた結果。スパムメールの判定率は,どのソフトでも上がっている(上)。ただ正当なメールの判定率は変化がないか,逆に下がっている(下)。なお,POPFileとMozillaは一定数の学習をしないとフィルタリングが実行されない。このためこの30通に加え,他のどのソフトも正しく判断したスパム,正当な両メールを30通ずつ追加学習させた。 |
その結果,どのソフトでもスパムメールの判定率は上がった(図5[拡大表示])。特にMcAfee SpamKillerの伸びが大きい。30通の学習により,新たに65通のスパムメールを正しく判断できるようになっていた。
これに対して,Norton AntiSpamの判定率の伸びは低かった。正しく判定できたスパムメールの数は18通しか増えていない。つまり学習させたメールでも,すべてが正しく判定できるようになるわけではない。
その原因としてまず考えられるのが,学習させたスパムメール自体にそれほど特徴がなかったこと。学習させた30通のスパムメールは,どのソフトも初期状態でスパムと判定できなかったものである。元々正当なメールとの特徴の差が少ないので,学習による効果が得にくかった可能性がある。
もう一つ考えられるのが,判定を間違えていたが学習させずに置いておいたメールが邪魔をしている可能性である。これが「逆学習」として働いてしまう。学習させた30通以外にも,スパムメールなのに正当なメールと判定ミスされたメールは多く存在する。これらをそのまま放置しておくと,ソフトはこれらのメールは正当なメールと見なすべきものだと判断してしまうのだ。
それが顕著に見られたのがMozillaである。Mozillaは初期状態で,1通を除くすべてのメールをスパムと判定した。このためまず,一度すべてのメールをスパムでない状態に戻した。次にどのソフトも判定ミスした30通と,どのソフトも判定できた30通をスパムとして学習させた。その結果,スパムメールと判断できたのは68通のみ。残りの370通は,すべて正当なメールと判断してしまった。学習させた60通以外はすべて正当なメールとして学習したためと考えられる。
つまりMozillaでは,最初に学習をきちんと実行する必要がある。Mozillaの場合,260通のスパムメールをスパムと学習させても170通しか正しく判定できるようにならなかった。このため検証の方法を変え,まず学習用の90通のメールだけを読み込ませて漏れなく学習させた。その後598通のメールを読み込ませると,172通のスパムメールをスパムと判定できた。スパムメールの学習数は60通だったにもかかわらず,260通学習させたときより判定数が増えた。
未分類状態が有効に機能する
ただし,少量の学習でも有効に働いたソフトが一つだけ存在した。POPFileである。初期状態ではMozillaと同じく何のフィルタリングもしないが,学習すると他のどのソフトよりも高い判定率を示した。これは,POPFileの学習の仕組みが他とは違うことに起因する。
通常のフィルタリング・ソフトは,メールをスパムか否かの二つに分類する。これに対してPOPFileは,まず最初にどんなカテゴリでメールを分類するか,ユーザーが設定できる。カテゴリの種類や数は,ユーザーが任意に決められる。スパムメールだけでなく,正当なメールも仕事に関連するものかプライベートのものかなど,内容によって複数のカテゴリに振り分けられる。
ただカテゴリを設定しただけでは,メールは分類されない。最初に読み込んだメールは,すべてまず「未分類」という状態になる。ユーザーは未分類のメールに対して,どれがスパムでどれが仕事のメールかを手動で学習させる。これによってPOPFileは,どのカテゴリにどんな内容のメールが属するかを覚える。次回からのメール読み込み時には,ここで覚えた傾向に基づいてメールを分類する。
学習させていないメールはすべて未分類のままなので,他のカテゴリに紛れ込んで適切でないルールを作成してしまう危険性を防げる。学習させていないメールが判定を邪魔しないため,少量の学習でも有効に働くようだ。
正当なメールも学習の必要あり
スパムメールの学習によって,正当なメールの判定率に変化があったかどうかも調べてみた。しかし,目立った向上は見られなかった。Eudoraにいたっては,逆に下がってしまった。正当なメールの中で,学習させたスパムと似た特徴を持つものがスパムと判断されるようになってしまったためと考えられる。
Eudoraは,他のソフトと比べても正当なメールの誤判定数が多い。これは「ユーザーに,ソフトも間違えるのだということを分かってもらうため初期状態ではわざとそうしている」(エッジソフトウェア事業部の中島一人氏)という側面もあるという。このためEudoraに関しては,スパムと判断されてしまった正当なメールをさらに30通学習させて追加検証した。
その結果,正当なメールの誤判定は一つもなくなった。やはり判定ミスをしたものはスパム/正当を問わず,きちんと学習させることが必要だ。
ただし,正当なメールを学習させてもソフトによっては有効に働かない場合がある。Eudoraの次に正当なメールの誤判定数が多いMcAfee SpamKillerでこの現象が見られた。Eudora同様,正当なメールなのにスパムと判断されてしまった15通を学習させ,再度同じメールを読み込ませてみた。
結果は,学習前と変わらなかった。学習させた15通は,スパムと判定ミスしたままだった。原因は,内容とは別のフィルタリング・ルールが邪魔をしていること。フィルタリングのログを見て推測した限りでは,あて先がなくBCCで送信されているメールはスパムと判断する,というルールに引っかかっているようだ。内容の判断とは別のルールなので,学習にかかわらず働いてしまう。



















































