![]() スパムメールの増加が日本でも深刻な問題となりつつある。これに対処するためのフィルタリング・ソフトが,2003年末に相次いで登場した。今回は,クライアント向けのフィルタリング・ソフトでどの程度スパムメールを排除できるか検証した。多くのソフトが,初期状態でも半分以上のメールを正しく判定できた。しかしまだ十分とは言えない。検証の結果,三つの課題が見えてきた。
スパムメールの増加が日本でも深刻な問題となりつつある。これに対処するためのフィルタリング・ソフトが,2003年末に相次いで登場した。今回は,クライアント向けのフィルタリング・ソフトでどの程度スパムメールを排除できるか検証した。多くのソフトが,初期状態でも半分以上のメールを正しく判定できた。しかしまだ十分とは言えない。検証の結果,三つの課題が見えてきた。
![]()
| ||
| ||
| ||
|
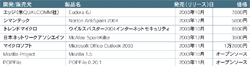


日本でも2003年10月から12月にかけて,スパムメールをフィルタリングする機能を持つ製品が相次ぎ登場した。メールサーバー側で動作するものと,クライアント側で動作するものの2種類がある。ただしサーバーに設置する場合,個々のユーザーによって「スパム」と判定する基準にずれがあるためどうしても強いフィルタリングはしにくい。その点クライアントなら,ユーザーの思い通りの強さでフィルタリングを実行できる。このため今回は,クライアントで動作する7製品を選んで評価した(表1[拡大表示])。
選ぶうえでは,二つの基準を設けた。まず日本語のメールに対応していること。もう一つは,単語の出現頻度など本文のテキスト情報を何らかの形で利用して判別していることである(別掲記事「メールを分類する二つの技術」参照)。本文を解析の対象にしていても,登録してあるキーワードが含まれているかどうかしか見ていない製品は対象外とした。
7製品のうち,メールソフトそのものにフィルタリング機能を組み込んだのがEudora,Outlook,Mozillaである。どれも,メールの受信時にスパムと判断したものを専用のフォルダに振り分ける。さらにMozillaでは,専用のフォルダ以外に入れてもスパム用のマークを付けることで見分けが付くようにしている。
残りの4製品は,メールソフトを問わずに使えるものだ。メールサーバーとメールソフトの間に介在する。対応しているプロトコルは基本的にPOP3のみ。まずメールサーバーから,POP3のクライアントとしてメールを受け取る。それがスパムかどうかを判定したあと,メールソフトに渡す形を採っている。ただMcAfee SpamKillerだけは,米Microsoft社のExchange ServerとOutlookが利用しているプロトコル「MAPI」にも対応している。
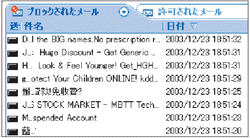
フィルタリング結果の見せ方はさまざまある。例えば,メールソフトにスパムメールを渡さないのがMcAfee SpamKillerである(画面1[拡大表示])。不快なメールがユーザーの目に触れずに済む。半面,必要なメールがスパムに判定されていないかどうか,別途確認しなければならない。一方,Norton AntiSpamなどこれ以外の製品はメールはすべてメールソフトに届けるが,件名を編集してスパムメールであることを明示する(画面2[拡大表示])。
実際に届いたメールを利用して検証
スパム対策ソフトの比較基準はただ一つ,いかに間違いなくスパムを判定するかである。より現実に近い状況で検証するために,日経バイトの編集部に届いた598通のメールを利用して判定能力を測定した。まず,これをスパムメールと正当なメールに人手で分類した。スパムメールと判断したものは,こちらが要求していないのに送られてきた広告や宣伝などのメールである。コンピュータ関連の企業から送られてきたプレスリリースやメールマガジンは正当なメールと判断した。
スパムメールではない正当なメールは,全体のうち160通あった。その多くが日本語のプレスリリースである(図1左[拡大表示])。英語のものは5通のみで,すべてプレスリリースだった。
一方のスパムメールは438通。英語のメールが圧倒的に多く,368通にのぼった(図1右[拡大表示])。ついで中国語のものが多い。内容は,アダルト関連のものや美容や健康に効く薬品などの宣伝,求人広告など多岐に渡った。内容があいまいで判断が付きかねるものも多かった。
三つの課題が見えてきた
評価を通して見えてきた課題は三つあった。まず,学習量が少ないと有効に働かないこと。学習とは,判定ミスをユーザーがソフトに明示的に教える作業のことである。学習した結果を次回以降のフィルタリングに反映させることで,ユーザーの満足のいく判定を実現しようとするものだ。しかし,少量ではそれほど大きな効果が得られない。つまりソフトを使い出した最初のうちは,かなりの量のメールをきちんと学習させなければならない。
二つ目は,日本語のフィルタリング能力の不足である。英語のメールは正しく判定できても,日本語のスパムメールはほとんど判断できていないソフトが見られた。日本語に即した処理を充実させる必要がある。
そして三つ目が,メールの意味を判断できていないこと。これはやや酷な注文かもしれないが,精度を高めるにはやがて必要となる可能性がある。ほとんどのソフトが,登場する語句の頻度を基にフィルタリングしている。このためそれが否定的に使われているのか肯定的に使われているのかなど,意味にまで踏み込んだ解析はできていないのが現状だ。



















































