| ||
| ||
| ||
|
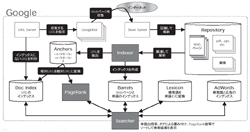

1万台超のサーバーで分散処理
Googleの基本アーキテクチャは一般的な検索エンジンのそれと大差ない。Webページを収集するロボット・プログラム(Googleでの呼称は「Googlebot」),収集したページをURLや単語に分解して索引を作成するインデックス作成プログラム(同「Indexer」),Googlebotが収集したWebページを格納するデータベース(同「Store Server」)とIndexerが切り出した要約を格納するデータベース(同Barrels),ユーザーが入力した検索語に応じたWebページを出力する検索プログラム(同「Searcher」)に大別できる(図3[拡大表示])。それぞれの役割ごとにクラスタ構成のサーバー機が用意され,「1万台以上のサーバー機」(Google社Director of TechnologyのCraig Silverstein氏)が稼動している。まず,Googlebotは「URL Server」の未訪問URLやPageRank値などの重み付けに従って,インターネット上のリンクを辿りながらWebページを収集する。収集したWebページのhtmlファイルはキャッシュとして保存する。Webページには固有のIDを(docID)を割り当てた後,データを圧縮して「Repository」に格納する。
次に,検索語とWebページを関連付けるインデックス情報を作成する。中心となるのはIndexerだ。IndexerはRepositoryに格納されたWebページを解凍し,リンク情報となるURLの抽出やWebページが含む単語の切り出し,単語の出現位置を解析する。切り出した単語や単語の出現位置を基に,単語とWebページを関連付ける索引を作成する。抽出されたURLは「Anchor」に格納され,Webページ間の相互のリンク情報としてPageRank値の算出に用いる。
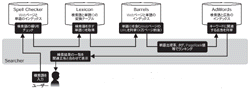
GooglebotとIndexerが中心となって作成したインデックスをユーザーが検索する際に利用するのはSearcherだ(図4[拡大表示])。検索語が入力された際,Googleサーバーのメモリー上に置かれる検索語と単語IDへのインデックス「Lexicon」を基に該当するWebページを検索する。Lexiconは単語をハッシュ関数(一方向関数)にかけて数値化したインデックスで,ハッシュ値がそのまま単語IDになる。ユーザーが入力した検索語はハッシュ値に変換され,単語IDの検索に使われる。文字列のような比較的短いデータを高速に検索するための一般的なアルゴリズム「ハッシュ法」を用いたものだ。
実際の検索時には,Searcherが検索語を含むWebページのリストを生成し,WebページのタイトルやURLといった検索語の出現個所,フォントの大小などによって重み付けをする。例えばURLのアンカー・テキストはそのWebページの要約として見ることができる。基本的に,あるWebページに対するリンクは,「<a href="http://itpro.nikkeibp.co.jp/NBY/" >日経バイト</a>」といったように内容を説明するテキスト(アンカー・テキスト)を伴うからだ。これにPageRankによる重み付けを加えて検索結果を並び替え,最終的な検索結果とする。
更新頻度の高いWebページに追従
検索結果の“もっともらしさ”に加え,検索サービスに求められる要件として,(1)検索可能なWebページの多さ,(2)Webページの更新が検索結果に反映されるまでの時間の短さ,の二つがある。両者を向上させるには,Webページを収集するロボット・プログラムの数と収集頻度を上げる必要がある。しかしむやみにロボットの数を増やして収集頻度を上げてしまうと,インデックスの作成時に発生するハードウェア負荷が検索システム全体のボトルネックとなりかねない。インターネットのトラフィックを無駄に増やしてしまうことにもなる。
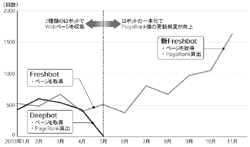
現在Googleが検索可能なWebページの数は約33億。33億のWebページを対象に,インデックスおよびPageRank値をほぼ毎日更新している。GooglebotによるインデックスとPageRank値の更新頻度がほぼ毎日となったのは,2000年5月頃からだ。それ以前のGoogleは,目的に応じて二つのGooglebotを使い分けていた(図5[拡大表示])。
Google社はGooglebotのアルゴリズムを明らかにしていないが,GooglebotがWebページを収集する際の挙動から,月に1回程度Webサイトに訪れるGooglebotが「Deepbot」,更新頻度の高いWebページにほぼ毎日訪れるGooglebotが「Freshbot」と呼ばれている。Deepbotはほぼ月に1回の頻度でWebページを訪問する。DeepbotによるWebページの収集後にPageRank値の算出が始まる。対してFreshbotは,ニュースサイトや日記などの頻繁に情報を更新するWebサイトを収集する。特にPageRank値の高いWebサイトには1日に複数回訪れ,インデックスに反映する。しかしPageRank値の更新は伴わない。Freshbotによるインデックスへの反映はあくまで暫定的なものであった。
現在のGooglebotは,Deepbotの挙動を示すWebページ収集がなくなり,Freshbotのみ(ここでは新Freshbotと呼ぶ)でWebページを収集している。新Freshbotによるページ収集とPageRank更新の頻度が上がったことにより,更新頻度の高いWebページのPageRankはほぼ毎日変動するようになった。
公開実験を基にサービスを追加
Webページ収集プログラムのGooglebotのアルゴリズムに変化が見られる以外,Googleが登場して5年を経た今もPageRankを基盤とする検索サイトとしての基本機能は変わっていない。日本語で利用できるサービスとしては,画像を検索する「イメージ」検索,ニュースグループを検索する「グループ」検索が加わった程度だ。ユーザーの検索行為を支援するソフトとしては,Internet ExplorerにGoogle用の検索窓を設けるアドインソフト「Google Toolbar」を提供している。
これらのサービスは,Google開発陣のアイデアを公開する「Google Labs」(http://labs.google.com/)から生まれたものだ。ここでユーザーのフィードバックを集め,公開実験の後に正式サービスに移行する。現在のGoogle Labsでは,Windowsのデスクトップ画面に検索用の入力ウインドウを設ける「Google Deskbar」,指定した検索語に関するWebニュースの更新をメールで通知する「Google News Alerts」など,計10個のサービスが公開されている(表[拡大表示])。
Google Labsの実験サービスをカテゴリ別に見ると,Google Deskbarに代表される検索支援アプリケーションおよびユーザー・インタフェースの工夫に関するものが多い。検索アルゴリズムの改良につながるものとしては,位置情報による検索「Search by Location」と関連語辞典の自動生成エンジン「Google Sets」がある。Search by Locationは,指定した住所や地域名,郵便番号から10km以内の住所情報を持つWebページのみを検索結果として返す検索サービス。Google Setsは,入力された単語の類義語や関連語を一覧表示する。例えば,「byte」と「bit」を検索語に指定すると,類義語として「word」や「nibble」といった情報量を表す用語,関連語として「CPU」や「Cache」といったコンピュータ用語が検索結果として表示される。GoogleはGoogle Setsのアルゴリズムを公開していないが,一般的な手法としては単語の出現確率や出現位置を基に自動抽出する方法がある。



















































