| ||
| ||
|

Googleがほぼ現在の機能を備えて姿を現したのは,1998年12月のこと(写真[拡大表示])。米スタンフォード大学の学生だったLarry Page氏とSergey Brin氏(両氏とも現在は休学中)は,同年9月にGoogle社を共同で設立。その後検索エンジンに必要なサーバーを確保する資金集めに奔走し,1998年12月のベータ版公開にこぎつけた(図1[拡大表示])。前身となる「BackRub」を改称したベータ版のGoogleは,1日に10万クエリーの検索処理をこなし,検索結果の確からしさから英語圏で人気を集めた。1999年2月に50万クエリー,同年6月に300万クエリーとユーザー数を伸ばし,2000年7月には検索サイト最大手の米Yahoo!社と提携。Google自身も2000年末に1億クエリーを超え,Yahoo!に並ぶ検索エンジン最大手に躍り出た。それから3年余りで,国内だけでもNECの「BIGLOBE」,ヤフーの「Yahoo! JAPAN」,エキサイトの「Excite」の検索エンジンとしてGoogleが標準になるなど,採用が相次いだ*1。2003年12月には国内大手のNTT-X「goo」もデフォルトの検索エンジンにGoogleを採用するまでに至ったのだ。
Webページのリンク構造で重み付け
Googleがここまで広まった理由は,(1)検索結果の“もっともらしさ”が他の検索サイトよりも高い,(2)2003年12月時点で33億を超えるWebページをほぼ0.5秒以下の時間で検索できる,という2点に集約されるだろう。
(1)のもっともらしさは,ユーザーが入力した検索語から満足度の高いであろうWebページをいかに推測するかにかかっている。検索結果を,多くのユーザーが満足できる可能性の高いWebページから順番に並び替える工夫が腕の見せ所となる。
ここで問題になるのが,いわゆる“スパムサイト”だ。一般に検索サイトでは,検索語を含むページを検索結果とし,検索語の出現部位や頻度を基準に並び替えて表示する。こうした仕組みはよく知られているので,検索結果での上位表示をねらう一部のWebサイトではWebページの内容とは関連しない語句を埋め込んで上位に表示させようとする。ほとんどの場合,スパムサイトはユーザーにとってノイズでしかない。スパムサイトを排除できるシステムでなければ,検索結果の満足度を下げてしまう。
リンクの価値を判定する「PageRank」
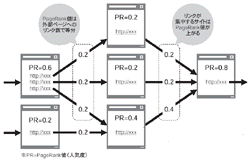
Googleが他の検索エンジンと異なるのはWebページの内容を評価する尺度として,Webページ間のリンクに着目した点だ*2。さまざまなWebページからリンクされているWebページは,より人気の高いWebページである可能性が高い。例えばページAからページBへのリンクは,ページAの作者がページBの内容に対して投じた投票とみなせる。
ただGoogleは,単純にリンク数のみをカウントして重要度を判定しているのではない。リンクの数で重要度を判定すると,ダミーサイトからリンクを張ることで意図的に重要度を上げようとするスパムサイトが上位に表示されるという問題が起こる。そこでGoogleはリンクの価値を判定する「PageRank」アルゴリズムを組み込むことでその問題を解決した。多くのWebページからリンクを受けているWebページからのリンクでなければ,PageRank値はそれほど上がらないようになっている。PageRank値の低いWebページからリンクを張ったとしても,PageRank値はほとんど上がらない。しかもPageRank値はリンクの数によって等分されるため,Webページの作者が厳選したリンクを重く見る構造になっている。こうした計算によって高いPageRank値を得たWebページを「高評価を得たページ」として,検索結果の順位付けに利用する。
この仕組みの特徴は,あるWebページのPageRank値を算出するために,リンク元のWebページのPageRankの値が必要になるという点である。このため他のWebページからのリンクがないページは除外し,リンクの連鎖が途切れないWebページの集合をPageRankの適用対象としている。Webページのリンク構造を一通り計算すると,再度起点としたWebページに戻ることになる。つまりPageRankの計算は再帰的なものになる。計算を繰り返すたびにPageRank値は異なる。PageRank値としてある初期値を適当に与えて計算を繰り返すことで,PageRank値のゆれを収束させていく仕組みになっている。Googleによると,322万のリンクを対象とする場合で50回を超える当たりからPageRankのゆれがなくなり,収束に向かうという。



















































