![]() フリー・ソフトウェアとして開発された全文検索システム「Namazu」は企業や官公庁を始め広く使われている。しかしその開発者である筆者は現在あまりNamazuを利用していない。彼自身の情報管理にはもっとシンプルな手法が適していると気づいたためだ。検索技術は適材適所が肝心である。
フリー・ソフトウェアとして開発された全文検索システム「Namazu」は企業や官公庁を始め広く使われている。しかしその開発者である筆者は現在あまりNamazuを利用していない。彼自身の情報管理にはもっとシンプルな手法が適していると気づいたためだ。検索技術は適材適所が肝心である。
![]()
ローテク検索に至る顛末
数年前までよく耳にしたが,最近はあまり聞かれなくなった話題は多い。例えば「情報の氾濫が深刻化して必要な情報を見つけ出せなくなる」などというのもその一つだ。実際に情報の氾濫が収まってきたのか,単にニュースとして取り上げられなくなっただけなのかは分からない。ただインターネットにおける検索技術が,情報の急激な増加に追いつくべく格段に向上していることは確かである。現在インターネット検索の代名詞になっている「Google」を提供する米Google社は,自社のミッションとして「世界中の情報を組織化し,世界中のユーザーがその情報を利用できるようにすること」を掲げている。Web上の情報へ大幅にアクセスしやすくなったのは,同社の取り組みに負うところが大きい。
Webは,インターネットを使える人の情報へのアクセスを容易にする。これまで手間がかかりすぎてアクセスできる人が限られていた情報がWebに登録され,多くの人が簡単に手に入れられるようになった。この結果,ITを使える人と使えない人の間に情報格差が生まれた。同時に,一般人と専門家の間で情報収集の手段に差異がなくなり,両者の情報格差が狭まるという現象も進行している。
こういった流れの中で筆者が興味を持って取り組んできたのは,(Google風に言うと)「自分の情報を組織化し,その情報を的確に利用できるようにすること」という実に自己中心的なテーマだった。といってもこのことを常に意識していたわけでなく,振り返ってみると結果的にそうなっていた,という感が強い。
実際,これまでに筆者が開発してきた検索システムは,すべて自分が使いたいという動機から生まれている。大量の文書を扱う全文検索システム「Namazu」,一つの巨大な文書を扱う全文検索システム「Sary」,日本語をインクリメンタル検索する手法「Migemo」がそれらである。
自分が開発したシステムを日常的に利用する中で,筆者は「技術的に高度なものが常に便利だとは限らない」ということを学んだ。利用局面によって使いやすい検索技術は異なる。目的によっては,シンプルな仕組みの方が有効に働く場合もある。
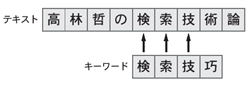 |
| 図●シーケンシャル検索の無駄 「検索技」までの3文字は一致するが,「巧」は一致しない。次回はテキストの「索」の位置から処理が再開されるが,「検索技」までのマッチングに要した3文字分の処理は無駄となる。 |
頭から1文字ずつマッチングする
検索技術と一口に言ってもその種類はさまざまだ。GoogleのようなWebの検索や,eコマースサイトでの商品の検索,画像処理による顔検索といったものまで多種多様である。今回はその中からテキスト情報の検索に関連する三つの技術について考えてみたい。文字列検索,情報検索,検索インタフェース,である。
この中で,テキスト情報の「検索」という言葉から最もイメージしやすいのが文字列検索だろう。文字列はまさに文字が列状に並んだもので,文章そのものと考えておけば差し支えない。文中から特定の言葉(キーワード)を探し出す処理が文字列検索である。
文字列検索の手法は大きく二つに分類できる。一つはテキストを頭から読み進めながら検索する手法,もう一つは処理を高速化するために,テキストとは別のインデックス(索引データ)を用いて検索する手法である。ここでは前者をシーケンシャルな文字列検索と呼び,後者をインデックス使用の文字列検索と呼ぶ。
仕組みがシンプルなのはシーケンシャル検索である。最も単純に実装すると,テキストの先頭からマッチングを始めてキーワードとテキストが一致すれば成功,一致しなければ1文字進める,というアルゴリズムになる。ただ,これでは無駄な処理が発生してしまう(図)。キーワードとテキストが途中まで同じだったが最終的に一致しなかった場合である。
このような無駄を省いて処理を高速化するアルゴリズムも考えられている。古典的なものには,Knuth-Morris-Pratt(KMP法)やBoyer-Moore(BM法)などがある。近年ではShift-Orアルゴリズムも,プログラムとして実装した際の処理の効率の良さで知られている*。
また検索時には,1文字程度の違いは許容してほしいという要求もある。図の例では「検索技巧」の検索は失敗したが,この程度の違いなら同じと見なしたい場合もある。こうした手法を「あいまい検索」と呼び,市販の電子辞書などで目にすることが多い。あいまい検索を使えば,うろ覚えの綴りでも単語が見つけられる。
うろ覚えの言葉を検索するためには,正規表現を使う方法もある。「検索○○論」のように漠然としたキーワードを指定する。正規表現の検索に対応したツールは,Unixの「grep」コマンドが有名である。grepで「検索.*論」で検索すると,「検索不要論」も「検索万能論」も一致する。
索引を利用して検索結果を出す
一方のインデックスを利用した検索方法では,書籍の索引と同様に索引データを作成する。この索引データを転置ファイルと呼ぶ。文中に現れる単語とその出現位置の情報を対応付けたものである。
インデックス作成時に重要になるのは,単語の区切り方である。単語と単語をスペースで区切る英語と違い,日本語は単語の区切りが明確でない。何らかの手法で文を区切る必要がある。主に二つの方法が知られている。一つは形態素解析システムを使って「単語/の/区切り/が/明白」のように意味のある単語単位で分割する。もう一つは,n-gramと呼ばれる方法。2~3文字ずつをひとかたまりにして「単語」「語の」「の区」「区切」「切り」のように分割する。
形態素解析システムを利用すると,検索ノイズを減らせる。分割された語が意味を持つ単語になっているので,部分的に文字が一致しているだけの意味のない語が検索対象外となるからだ。長い単位で語を区切れるので,インデックスのサイズも小さくできる。半面辞書に登録されていない語は正しく区切れず,検索漏れが発生する。特に「モーニング娘。」のように,日本語として一般的でない表現の解析に弱い。
こうした問題はn-gramの手法では発生しないため,検索漏れは基本的に起こらない。その代わり,検索ノイズが増えるのがデメリットである。例えば「パン」で検索して「ルパン」が見つかってしまう。
筆者が開発を始めた(現在はグループで共同開発している)Namazu という検索システムでは,形態素解析システムを利用している。おかげで,インデックスを小さくできた。文字を区切る部分を形態素解析システムに任せるので,Namazu自体の処理も単純になった。ただし検索漏れが生じやすいことを考えると,正しい選択だったか疑問が残る。この辺りのトレードオフは検索システムを設計する上で大変難しい。
インデックスのデータをどのような形式で保持するかも重要なポイントだ。形式はいくつもあるが,中でもSuffix Arrayはデータ構造が極めて単純で扱いやすいという利点を持っている。ある文字列が出現するテキスト中の位置をポインタとして配列に格納しておく。検索時にはこの配列を参照して,目的の文字列がどこにあるかを探す。筆者が開発したSaryという検索システムは,Suffix Arrayを利用して巨大なテキスト・ファイルを高速で検索できる。論文データベースからの例文の検索や,ゲノム・データベースを検索する用途などに応用されている。
インデックス作成にはコストがかかる
シーケンシャルな文字列検索とインデックス使用の文字列検索は,利用局面によって使い分ける必要がある。検索するデータの量と頻度によってどちらが適切かが変わってくる。
検索対象のテキストが小規模な場合は,シーケンシャルな文字列検索で十分な場合が多い。しかし規模が大きくなると,頭から1文字ずつ検索したのでは時間がかかる。このため,インデックスを導入する必要が生じる。
インデックスの必要性は,検索の頻度にも左右される。月に1回しか検索要求がなければ検索に数分かかっても不都合はないかもしれない。しかし毎秒何十件もの検索要求がある用途では,とにかく速くする必要があるだろう。
ただし,インデックスの導入にはコストがかかる。ディスク消費量の増加やシステムの複雑化といった導入に伴うコストを踏まえ,速度とのトレードオフを検討しなければならない。さらに,タイミングによっては検索漏れが発生することに注意する必要がある。インデックスの更新には時間がかかるため,1日1回や1時間に1回といった間隔で更新されるのが一般的である。この結果,更新間隔の間に作成された文書が検索にヒットしないという現象が起きる。
この問題に対する理想的な解決策は,文書が作成/更新されたタイミングでインデックスを更新し,常にインデックスを最新に保つことである。そのためには,ファイル・システムと検索システムを連動させる必要がある。既にWindowsには,格納したファイルから自動的にインデックスを作成する技術が導入されている。こうした仕組みは,OSやミドルウェアにさらに広く採り入れられていくと考えられる。
検索を巡る二つの法則本記事を執筆するにあたって,検索とは何かについて改めて考えてみようと試みた。最初にしたことは,平凡に辞書で「検索」を引くこと,次はGoogleで「検索」を検索することだった。考えてみようと思って最初にしたことが,二つとも検索だったのだ。このことから,一つの仮説が浮かんだ。もしかしたら「考える」という行為を「検索」で代用しようとしているのではないか。 調べて考えることは大切だと言われる。現在はGoogleや電子辞書のおかげで,調べることはずいぶん簡単になった。しかしそのぶん考えることに時間を費やすようになったかというと,そうでもないようだ。レポートを書く代わりに似たような文書をWebで検索して,少々修正して提出する,という行動は端的な例だ。このことから「調べることは簡単になっても,考えることは簡単にはならない」という法則を思いついた。 これはなかなかよくできた法則だと思って喜んでいたところ,ちょうど知人から一通のメールが届いた。呆れるような質問だった。調べればすぐ分かることをわざわざ訊くな,と腹が立った。そしてこのことから,「調べることは簡単になっても,調べるとは限らない」という第二の法則の発見に至った。自分だって人のことは言えない。我ながら耳が痛い法則である。 |
高林 哲 Satoru Takabayashi産業技術総合研究所研究員1997年に全文検索システム「Namazu」を開発。以来,多数のフリー・ソフトウェアを開発している。研究員という肩書きの割には,「論文の数 << 雑誌記事の数 ≒ フリー・ソフトウェアの数」という状況が続いている。http://namazu.org/~satoru/ |



















































