検証2
どのソフトでも学習は有効
| ||
|
あらかじめ辞書登録しておくのではなく,ユーザーが過去に確定した情報を利用して未知語を正しく変換しようとするのが学習の仕組みである。ただこれがうまく働かない場合があるというのが,二番目の課題だ。
学習はすべてのソフトが持つ基本的な機能である。過去の情報が履歴として蓄えられ,次回以降の変換時に使われる。
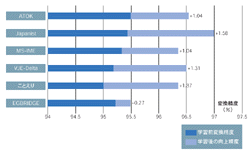
その効果を確かめるため,一度学習させたあとに評価用のコーパスを変換させてみるという実験を実施した。コーパスには,各ソフトが苦戦した日経バイトのデジタルカメラ関連の記事を利用した。
ただ,学習させるデータには別の文章を使った。同じ記事を2度変換させるよりも,現実的な利用場面に近いからだ。実際の使用局面で,まったく同じ文章を2回続けて打ち込むことは考えられない。代わりに,同じような言葉を使った似た文章を繰り返し入力することはよくある。そこで最初に,『日経エレクトロニクス』のデジタルカメラの記事を手作業で入力して学習させた。次に日経バイトの記事を変換してみた。
その結果,どのソフトでも精度の向上が見られた(図5[拡大表示])。理由は二つある。(1)未知語を覚えられたこと,(2)語順が入れ替わったこと,だ。
特に大きかったのが(1)である。日経バイトの記事には,「スミア」「インタライン転送」といった,通常あまり使われない技術用語が多く含まれている。初期状態では,多くのソフトがこれらの語で変換ミスを起こしていた。
たとえば「スミア」に関しては,「炭/あ」「炭/亜」「隅/あ」といった具合に間違えてしまう。無理矢理文字を区切り,辞書登録されている語に変換しようとしているのが分かる。ただしその中でことえりは,「すみあ」とひらがなのままだった。未知語だと判断したため,変換を諦めたと考えられる。無理に変換しようとして区切りを間違えるよりは,ユーザーの心証は良い。区切り間違いを訂正する手間が必要ないからだ。
文節区切りを間違うと,周りの語を巻き込んで大きなミスを引き起こしてしまう場合もある。「これがスミアである」という文章が,「これ/ガス/美亜である」「これが/住み/亜/出/ある/」などと変換されてしまう。
EGBRIDGEだけは,「スミア」や「インタライン転送」などが初期状態で変換できた。学習の結果,EGBRIDGEであまり精度が向上しなかったのは,このためだと考えられる。
(2)は,同音異義語の変換間違いを起こしていた場合に効果があった。かな漢字変換ソフトは一般に,最後に確定した語を次に優先して出す。このため,同じ文脈でその語を使い続ける限り,正しい結果が出てくることになる。
今回の実験では,「でんか」という語で効果が見られた。デジタルカメラの記事には「電荷」という語が含まれているが,これを「電化」と変換してしまう誤りがほとんどのソフトで見られた。「電化」の方が一般的な語であるため,当然の結果とも言える。これを一度「電荷」と確定すると,次からは優先して「電荷」が結果として出てくるようになった。
「光学」や「素子」でもこの効果は確認できた。「光学ズームレンズ」の「こうがく」を「工学」や「高額」,「撮像素子」の「そし」を「阻止」と変換してしまうソフトが多かった。学習後はこのどちらも,正しく変換できるようになった。ちなみにEGBRIDGEだけは,このどちらも初期状態で正しく変換できていた。
一方で,学習させたことによる弊害もあった。語順が入れ替わったことで,別の文脈で同じ読みの語が使われていた場合に変換間違いが起こったのである。日経エレクトロニクスの記事に含まれる「多画素」という表現を変換するために,「た」を「多」と学習させた。これが原因で,VJE-Deltaでは元々正しく変換できていた「他の」という表現が「多の」に変わってしまった。
学習が働かない語がある
さらに,一度学習させたはずの語が次回に反映されないという現象も確認できた。先に入力した文章に含まれるすべての語が,正しく変換できるようになるわけではない。学習がうまく働かない語は,どのソフトにも共通していた。「画素」である。
日経エレクトロニクスの文章には,「多画素化」「1つの画素」など,「画素」という語が多く出てくる。初期状態では「田が楚歌」「1角が祖」など正しい結果が出ないので,人手で正しく変換させて確定した。通常は,2度目に同じ「画素」を入力したら正しく変換されるはずである。しかしこの語に限っては,これが当てはまらない。相変わらず変換ミスし続ける。つまり語によっては,学習が有効に働かないものがあるのである。
「画素」が学習後もうまく変換できない理由として考えられるのは,まず2文字と語の長さが短いこと。語は,短ければ短いほど変換が難しくなる。そのぶん同音異義語が増えるからだ。
ただしそれだけでは説明として不十分だ。短い語でも,きちんと学習される例は少なくないからだ。
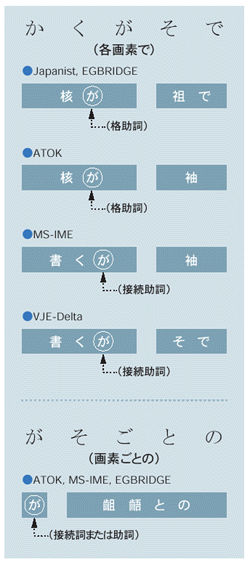
「がそ」を学習できないのは,他の語に間違われやすい「が」と「そ」という二つの文字から成り立っているからだ。特に難しいのが「が」である。「が」は,「私が」という場合の格助詞や,「今日は寒いが」といったときの接続助詞としても使われる。「各画素の」という表現では,このどちらかに判断されてしまう(図6)。
これだけが理由ならば,「画素」で始まる語については正しく変換できてもよさそうに思える。助詞としての「が」とは判断されないからだ。しかしそれでも変換に失敗する。文頭にある場合は,接続詞の「が」と間違えている可能性が考えられる。なお先頭の「が」でも,助詞と判断している可能性はある。名詞だけを変換して確定し,次に助詞から書き始める場合もあるからだ。
「そ」もやっかいだ。「その」「そこ」などで使われる指示詞の「そ」に間違われやすい。この場合,「がその」と入力されると「が/その」と区切られてしまう。
対症療法的な工夫しかできない
だからといってメーカーが安易に「画素」を辞書登録してしまうと弊害が大きい。「わたしがそのとき」が「私画素の時」,「かれがそとに」が「彼画素とに」などと変換される危険性が考えられる。
こうした現象を防ぐための工夫もいくつか見られた。だが対症療法的で,根本的な解決にはなっていない。
例えばATOKでは,「画素の」では変換に失敗するが「100万画素の」なら問題なく変換できる。「万画素」で辞書登録をしているようなのだ。「がそ」の前に「万」が付いていれば,「画素」と判断しても大丈夫ということなのだろう。ただ当然ながらこれでは,「5画素」などの表現には対応できない。
MS-IMEでは,「画素」の後ろにくる言葉によって結果を変えている。「画素」で文章が切れていたり,後ろに「製品」など名詞が接続する場合は,正しく変換できていた。このため,ATOKでは失敗する「5画素」も問題なく変換できる。半面「画素と」など,後ろに助詞が続くと間違いが起こる。ATOKでは「11万画素と」は正しい結果になるが,MS-IMEでは「11万が外」となる。
この点健闘していたのがVJE-Deltaである。どちらの工夫も盛り込まれているようで,「5画素」「11万画素と」ともに正しい結果が出る。ただし完璧ではなく「各画素の」という表現には対応できていない。



















































