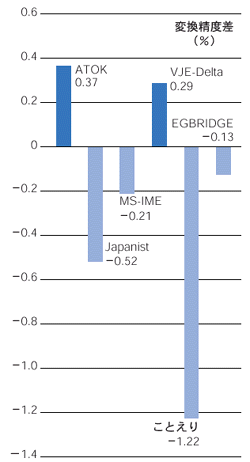
検証1
対応し切れていない語彙空間がある
| ||
|

かな漢字変換ソフトが対応できていない語彙空間として目立つのは,人名,新語,そして口語である。
人名の変換が困難なのは,まず「氏」「家」のように短い単位の付属語が付くことが多いことからだ。人名と付属語が一緒になって,別の一語として解析されてしまう場合がある。
分かりやすい例が,日経新聞の政治記事のコーパスにあった「かめいし」である。正解は「亀井氏」だ。しかし,同じ読みで「亀石」という語も存在するため,ATOKとVJE-Deltaは「亀石」と変換した。この二つは,多くの文字数を少ない文節で変換できる結果を正しいと判断している(別掲記事「かな漢字変換で使われる二つの方式」参照)。このため,区切りが二つになる「亀井/氏」よりも,一つで済む「亀石」を正解としていると推測できる。
付属語が助詞に解析されてしまうという問題もある。今回のテストでは,「橋本派と堀内派が」でその現象が見られた。Windowsの四つのソフトのうち,正しく変換できたのはVJE-Deltaだけ。ほかのソフトは,「は」を格助詞だと判断し,「橋本は」と変換してしまう。これが原因であとの解析が崩れ,場合によっては文節区切りを誤る。例えばATOKでは,「橋本は/砥堀/うち/はが」となってしまった。
こうした区切り間違いは,短い単位の文字列で変換すれば防げることもある。ただし,それが常に効果的とは限らない(別掲記事「入力する文字長は精度に影響せず」参照)。
辞書登録量の勝負になる
人名は数が多くて辞書に登録しきれないことも,変換を難しくしている。日本人の姓だけで,その種類は20万とも30万とも言われている。名前はこれを上回る数になるだろう。すべて網羅するのは不可能に近い。
また,人名は安易に辞書に登録できない。「珍しい人名を入れたために,他の一般的な表現の変換に失敗してしまうこともある」(バックスの萩原社長)。このため,通常の辞書と人名/地名用の辞書を分けているソフトが多い。この辞書は人名/地名用変換モードにして初めて有効になることが多いため,デフォルトの変換モードでは利用できない。
同様の理由で通常の辞書への登録が難しいのが,新語や時事用語のたぐいである。専用の辞書が用意されているソフトも多い。これにどのくらい単語が登録されているか,そしてこの辞書をどのモードで参照するかによって,変換精度は変わってくる。
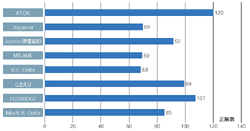
最近話題の語を150語集め,その変換精度を比較してみた(表2[拡大表示])。結果には大きな差が出た(図4[拡大表示])。ATOKやEG-BRIDGEの成績が良かったのは,デフォルトで話題の語を集めた辞書を変換に利用しているためだ。同様の辞書はJapanistも持っているが,Japanistはデフォルトでそれを利用しないため結果は芳しくなかった。設定を変えて辞書を利用してみたら,結果が大幅に改善された。またこの点についてのみ,辞書を更新しているMacVJE-Deltaもテストした。専用の辞書を持たない割には,正答数が大幅に増えている。やはり辞書の効果は大きい。
やはり口語表現には弱い
語彙空間の違いが顕著な例として,口語表現が挙げられる。かな漢字変換ソフトが主にターゲットとしているのは,書き言葉である。パソコンは主として,文書やデータの作成に使われてきたからだ。しかし最近では,メールやチャット,Web上の掲示板への書き込みなど,口語表現を使う場面も増えてきた。
このため「通常のモードでも,一般的に使われる口語表現ならば変換できるようにしている」(ジャストシステムATOK製品開発部の新田実氏)。確かに『日経エンタテインメント!』のインタビュー記事の変換結果を見ると,「わかんないのよ」のような撥音便の表現や,「いい味するじゃん」といった砕けた語尾の表現など,よく使われる語については,どのソフトも通常のモードで変換できる。
ただし,一歩そこから踏み出すと途端に怪しくなる。「見せとこうと」が,「店とこうと」,「って言われて」が「っ低割れて」などと変換される。デフォルトで口語体に対応しているため成績が良かったEGBRIDGEでさえ,少し変わった表現には対処できなかった。「汚(きたね)え」が「北ね絵」になるなど,文節の区切り間違いを起こしてしまう。
モード切り替えの有効性はまちまち
こうした口語独特の表現に対応するため,口語変換専用モードを設けているのがATOK,MS-IME,VJE-Deltaである。効果を調べるためモードを切り替えて日経エンタテインメント!のコーパスを変換させてみた。期待ほど大きな効果は得られなかった。
変換精度が向上したのはATOKのみ。「いなけりゃ」が「異な毛りゃ」,「覚悟しとかなきゃ」が「覚悟し説かなきゃ」,「汚え」が「北根絵」と誤変換されていたものが,正しく変換できるようになった。
だが変わらないものも少なくない。例えば「見せとこう」は「店とこう」のままだったし,「うん,」は「運,」になってしまう。通常モードと比較した時の精度向上は0.3%にとどまった。
MS-IME,VJE-Deltaの二つは,モードを切り替えても変換結果に変化が見られなかった。これは,コーパスの選び方にもよるだろう。各ソフトとも口語モードで対象にしている語彙は限られており,それに合致する表現でなければ結局対応できない。
VJE-Deltaの口語モードは,「いってきまーす」などのように,間に「~」や「ー」が入った表現などで効果があるようだ。またMS-IMEの口語モードでは,「ご飯いかないかい」といった,友人同士でチャットをしている際によく使われるような表現に対応しているという。ただし表現を少し変えて「お茶飲まないかい」と入力してみると「お茶の間内科医」になってしまう。
モードの切り替えは面倒
モード切替には,ユーザーに切り替え操作を強いるという問題もある。いくら特定の表現がうまく変換できても,入力する文章に応じてモードをいちいち切り替えたくない。公式な文書を作成しながら友人に砕けた文体でメールを書くことだってあるからだ。ユーザーに切り替えを意識させなくても,さまざまな表現を正しく変換できた方が望ましい。
実際,ユーザーはあまりモードを切り替えていない。マイクロソフトは,同意が得られたユーザーから,変換ミスの情報などをインターネット経由で送信してもらう「カスタマエクスペリエンス向上プログラム」を実施している。この結果,「変換モードはいくつか用意しているが,実際にユーザーは使っていないことが分かった。モードを切り替えずに,幅広い表現に対応する必要がある」(マイクロソフトプロダクトディベロップメントリミテッドオフィスサービス開発統括部インプットメソッドテクノロジーグループプログラムの佐藤良治マネージャ)。
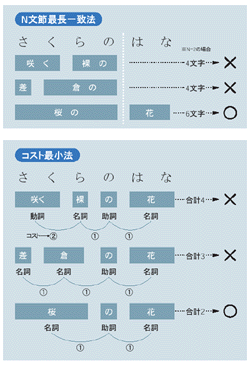
かな漢字変換で使われる二つの方式かな漢字変換ソフトに対してユーザーが入力する文字列は,単なるひらがなの羅列でしかない。これを正しい単位に区切り,適切な漢字を選択するのにはいくつかの手法がある。 中でも有名なものに,N文節最長一致法とコスト最小法と呼ばれる方法がある(図A[拡大表示])。どちらも有効な手法であるとされ,優劣は一概に判断できない。N文節最長一致法はATOKやVJE-Delta,Japanist,EGBRIDGEが採用しているし,コスト最小法はMS-IMEやことえりが使っている手法だ。 N文節最長一致法は,できるだけ長い文字列を少ない文節数で変換できたものを正解とする。文章は多くの場合,細かく区切るほど意味を成さなくなる。長い単位で意味のある語ができるひらがなが並んでいれば,その方が確からしい。 一方のコスト最小法は,語と語がどの程度つながりやすいかという情報を元に正解を決定する手法である。例えば名詞は助詞と接続することが多いが,動詞と動詞が続いて登場することはあまりない。こうした情報をあらかじめコストとして数値化しておき,変換時に参照する。 つながりやすいものはコストが低く,つながりにくいものは高い。さまざまな可能性を試してみて,最も低いコストで変換できるものを正解とする。 ただし各社とも,これらの手法だけで変換結果を決めているわけではない。これらを拡張し,独自の手法を編み出している。語の係り受け関係や,その語がどの程度一般的なものかといった情報も利用して,より適切な結果を出す工夫をしている。 |
入力する文字長は精度に影響せずパソコンで日本語を入力するとき,どの単位で変換キーを押すかは人によって異なる。1文節ずつ入力して変換する人もいれば,1文を一気に変換させる人もいる。 それぞれに,利点と欠点が考えられる。短い単位で入力した場合,文節がユーザーによってあらかじめ区切られているので文節の区切り間違いをする確率が減る。ただし一緒に入力された他の単語の情報が使えないので,同音異義語の選択が難しい。長い単位で入力した場合はこの逆になる。区切り間違いをする危険性は増えるが,一緒に入力された語を参考にすれば同音異義語の選択ミスを減らせそうだ。 実際,ソフトによって結果は分かれた(図B)。『日経レストラン』のコーパスを句読点単位で長く区切ったものと,文節単位で細かく区切ったものを用意して試してみた。短く区切った方が精度が良いものがATOKとVJE-Delta,その他は逆だった。 ただし,その差は0.1~0.5ポイントとわずかである。「どちらの入力方法でも変換精度に大きな差はない」(マイクロソフトプロダクトディベロップメントリミテッドの佐藤氏)と言えるだろう。 その中で一つだけ,1ポイントを超えたのがことえりである。ことえりはマニュアル等で「長い単位で入力した方が結果が良くなる」と,長い単位での入力を推奨している。実験でもそれが実証された形となった。 |