 |
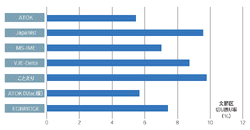
| 図3●文節区切り誤り率 ユーザーにとってストレスの大きいエラーである。変換キーを押した回数に対して,文節区切りが発生した割合を示した。 |
未知語と同音異義語の変換が課題
ミスの内容を細かく評価すると,現状のかな漢字変換ソフトが苦手としている点が浮き彫りになった。ミスのほとんどが,次のどちらかに当てはまる。(1)使われる言葉がソフトが想定している言葉の範囲(語彙空間)からはずれた場合,(2)同音異義語が多くある場合,である。(1)は,辞書に登録できる言葉がある程度限定されるために起こることだ。ソフトは辞書を参照してひらがなを漢字交じりの文字列に変換する。つまり辞書に登録されていない言葉は変換できない。「一番ユーザーにストレスを与える語句の区切り間違いのミス」(バックスの萩原健代表取締役社長)も,辞書に言葉が登録されていない場合に多く発生する(図3[拡大表示])。だからできるだけ多くの単語を辞書に登録しておきたい。
しかし現実には,すべての言葉を辞書に登録できるわけではない。特定の業界でしか使われない専門用語や,常に変化していく口語体や人名,新語などを完全に網羅するのは不可能だ。量が多すぎる。
しかも,手当たり次第に登録すればよいというものでもない。あまり使われない語を登録してしまうことが一般的な語の変換に悪影響を及ぼす可能性があるからだ。汎用的な語かそうでないかをどこかで切り分け,辞書登録すべきかどうかを判断しなければならない。つまり,あえて登録を見送った語もある。こうして作られた語彙空間が入力する文書の語彙空間とずれていると,変換ミスが頻繁に発生することになる。
(2)は,ひらがなを入力して漢字に変換するかな漢字変換ソフトでは避けては通れない問題である。一つのひらがなに複数の変換候補があると,そのどれを選択してよいか分からない。より汎用的な語や以前確定したことのある語が優先して出てくることが多いが,必ずしもそれが正しいわけではない。
既に工夫は盛り込まれている
まだ完全ではないが,これらの問題に対処する方法も考えられている。言ってしまえばかな漢字変換ソフトの初期から続く“永遠の課題”だからだ。
現在のところ,語彙空間のずれを解決するために盛り込まれた手法は二つある。一つは,入力シーンに合わせて変換結果を変えるという方法だ。語句や表現の種類によって,変換させる際に考慮すべきポイントは異なる。このため入力される文章の種類があらかじめ分かっていれば,それに合った辞書やアルゴリズムを使い分けることで変換精度を高められる。例えば口語体の文章を入力する時には「口語モード」に切り替えたり「話し言葉辞書」を使ったりする。
もう一つは,過去の学習結果を利用すること。辞書にあらかじめ登録されていない語がユーザーによって入力されたときに,ユーザーがどう変換したかを覚えておく。次に同じ語が入力されたら,その情報を使うことで正しく変換できるようにするというものだ。
同音異義語の変換ミスを解決するために使われているのが,「共起情報」だ。一緒に使われることが多い語の組み合わせを利用する。例えば「花」は「咲く」,「鼻」は「嗅ぐ」という言葉と一緒に使われることが多い。このため,「はな」と入力された時,前後に「咲く」があれば「花」,「嗅ぐ」があれば「鼻」に変換する。こうした工夫で,同音異義語の変換ミスを減らす。
三つの課題が浮かび上がった
こうした工夫がどれくらいの効果を発揮しているか調べるため,今回は3種類のテストを実施した。モードや辞書を切り替えて変換させてみる,学習前と学習後で変換結果がどう変わるかを調べる,同音異義語の組を入力してそれぞれがきちんと変換できたかどうかを見る,の三つである。テストの結果,どの工夫も変換精度の向上に少なからず役立っていることが確認できた。
しかし同時に課題も見えた。まず,対応できている語彙空間はやはり限定的だということ。モードや辞書の切り替えが有効に働く場合もあるが,その効果は限定的である。口語体の専門辞書に登録されている語は限られているため,口語を入力しても同じ誤りを繰り返す場合が多い。またモードの切り替えは,ユーザーに負担を強いる。入力する文章の種類を変えるごとに,かな漢字変換の設定をいじるのは面倒だ。入力中の文章が,どのモードに適しているかを正しく判断するのも難しい。一つのモードで幅広い表現が変換できた方がよい。
次に,学習のメカニズムに不足があること。何度変換しても,学習が働かない語が存在する。この場合ユーザーは,入力のたびに同じ変換ミスを目にする羽目になる。一度確定済みの語を,ソフトが理解してくれないことによるストレスは大きい。どんな語であっても,一度学習させた結果は次回以降に正しく反映してほしい。
最後が,共起情報が十分に利用できていないこと。同音異義語が複数存在する場合でも,定型的な表現ならば現状でも正しく変換できる。しかし少し表現を変えたり,別の語を途中に挟んだりしただけで途端に間違った結果を出すことが多い。もう少し前後の語を勘案できれば,ユーザーの求める結果が出せそうだ。



















































