![]() システムのアーキテクチャはさまざまな構成要素のトレードオフを考慮したうえに成り立っている。場合によってはまったく別のアプローチを採るべきこともある。基本的には抽象度を高めることにより生産性や保守性を高めている。ただし抽象化にはその前提となる条件が存在する。これを忘れ「抽象化のやぶれ」に遭遇するとプロジェクトの失敗につながる恐れがある。
システムのアーキテクチャはさまざまな構成要素のトレードオフを考慮したうえに成り立っている。場合によってはまったく別のアプローチを採るべきこともある。基本的には抽象度を高めることにより生産性や保守性を高めている。ただし抽象化にはその前提となる条件が存在する。これを忘れ「抽象化のやぶれ」に遭遇するとプロジェクトの失敗につながる恐れがある。
![]()
| ||
| ||
|


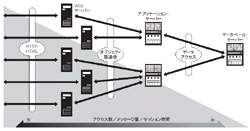
ミドルウェアは階層型の構造になっている。つまりOSとプロトコル・スタック,インフラレベルのミドルウェア,基本フレームワーク,基本サービス,ドメイン依存サービス,アプリケーションである(図1[拡大表示])。階層構造を採ることにより一般開発者から内部実装を隠蔽している。そのぶん一般開発者は,抽象度の高いプログラミング・モデルを利用できる。アプリケーション機能が高度化し,それに伴い技術が複雑化しても,適切なアーキテクチャとデザイン・パターンを選択すれば問題は発生しない。しかし,本当にこのアーキテクチャで良かったのだろうか。その検証は厳密にはなされていない。
階層型とブローカ・アーキテクチャの選択
代表的なアーキテクチャとして,階層型アーキテクチャとブローカ型のアーキテクチャを考えてみよう。ブローカ型は一般に分散オブジェクトで使われるアーキテクチャで,アプリケーション・サーバーとクライアント間の通信や起動メカニズムの基本に用いられている。
それぞれの課題はその構造に起因する(表1[拡大表示])。階層型では個々の階層ごとにインタフェースを定め,それぞれの間でやり取りが発生する。このため,階層間インタフェースの設計が悪いと,ある階層の変更が複数階層に波及したり,ある階層のムダが上位の階層に影響したりする。
一方ブローカ型では,リクエストを媒介する存在が必要だ。分散オブジェクトの場合,クライアントはサービスを実装するオブジェクトに直接アクセスしない。プロキシと呼ぶローカル・オブジェクトにアクセスする。プロキシが媒介役となる。通常プロキシはサービスと同じインタフェースを持ち,通信データ形式への変換や,インタフェース型チェックによる型安全性を保証する機能を持つ*1。場合によってはキャッシュ機能を提供して性能向上にも寄与する。
ブローカの起動メカニズム(アクティベータまたはディスパッチャ)はプロキシと同じ間接参照をサービスの起動に使ったものだ。すなわち,サービスのオブジェクトはまずプログラムをディスパッチャに登録しておく。ディスパッチャはクライアントの要求を待ち続ける。要求を受信すると,要求先のサービスを登録情報から検索して起動する。
ブローカ・アーキテクチャでは,プロキシが介在することによってクライアントとサービスを分離できる。結果としてサービスを提供する位置の透過性を与える。半面プロキシは間接参照であり,効率の劣化を招く。また現実問題としてデバッグが困難といった課題がある。
N層モデルのリソース配置はどうあるべきか
さて,現在最も普及しているアーキテクチャは,Webサーバー,アプリケーション・サーバー,データベース・サーバーを配置するN層モデルである。このN層モデルはトランザクション処理を効率的に実行するための代表的なアーキテクチャである。この配置形式がなぜ普及したのかを物理法則に基づいて評価してみよう。
まずネットワークからの入り口となるWebサーバーは,インターネットからの要求を受信するため同時アクセス数やアクセス・メッセージ量が多く,クライアント入力操作によるセッション継続時間が長い。ただここでの処理は,データベースへ結果を格納するまでの一時的結果をメモリーに保持するのが主な役目だ。セッションごとの独立性が高く,処理データを個別に管理できる。この場合複数台のマシンによる並列分散処理が適している。
一方バックエンドのデータベース・サーバーは,各セッションで生成,更新されたデータを共有データベースに格納する。つまりトランザクション処理に基づく共有アクセスの排他制御や同期制御が必須である。それゆえ,物理的に複数マシンに分散した構成は適切ではない。データベース・アクセスはWebサーバーのHTTP要求受信処理のような非同期処理に比べ,同期型で許容コネクション数は限定される。これがコネクション・プールが存在する理由でもある。しかし,良い設計をすればコネクションを利用するトランザクション時間を短くし,性能を向上させることが可能である。
要するに,N層モデルではネットワークの入り口からバックエンドに向かってリソースの利用コストが高価になり,その分設計に対する要求も高くなる(図2[拡大表示])。したがって,入出力にかかるコストが高いデータベース・アクセスより,中間層の安価なオブジェクト・キャッシュに処理を任せて性能向上を図るのがリーズナブルである。ただしデータベース・アクセスをうまく最適化することも十分考慮しておきたい。例えばテーブルの結合処理はデータベースに任せた方がよい。結果セットをオブジェクトとして取り出し,オブジェクトのリンクをたどって結合操作をさせるより性能がいいからだ。また,むやみに結合操作が発生するテーブル設計は,実際の利用パターンを考えると望ましいことではない。
物理法則に即したシステム構成
もちろん,企業システム全体で再利用性の高い,安定したデータモデルはデータ中心アプローチで考慮するのが重要である。このように,物理法則と実際の利用パターンを考慮することが個別のデザイン・パターンの考慮より重要である。
物理法則の制約としては,ネットワークやディスク入出力の転送時間とそれに伴い発生する遅延,現実に使えるリソースの量,適切な応答時間などがある。物理法則の制約が原因となって技術的なトレードオフが発生する。これを解決するためのアーキテクチャやデザイン・パターン,プロトコル,データモデルなどが考案され,実証されている。例えばこんな具合だ。
(1)関係データモデルではレコードの順序に意味を持たないので,ディスク入出力が最小となるようレコードを並べ替えるクエリープランを選択する(ディスク入出力の転送時間を考慮するデータモデルの採用)。(2)分散システムではデータの鮮度と同期化のためのデータ量増加のトレードオフを考慮してプロトコルを考案する(ネットワークのデータ転送時間を考慮するプロトコルの考案)。(3)ジャストインタイム・コンパイラでは最適化処理時間とコンパイル対象プログラムの実行効率のトレードオフで最適化アルゴリズムを考案する(有限時間の制約を考慮する最適化アルゴリズムの適用)。
物理法則の制約は今後どんなに技術が進歩しても,本質的に解決できない問題である。よりよい対処法や回避策が考案されるにすぎない。しかし中には,従来とはまったく異なる対処法で以前の対処法を駆逐する,破壊的(disruptive)技術も出てくるだろう。



















































