| ||
| ||
|


もう一つ検索条件の記述で気を付けなければならないのが,日付の取り扱いである。元々標準のSQLでは日付型は定義されていなかった。このため,実装がデータベース・ソフトによってまちまちなのである。SQLで記述できるのはあくまでも文字列なので,文字列で書いた日付を何らかの形で日付型のデータに変換してやらなければならない。例えば処理系によっては日付に変換する関数を使うものもあるし,定数の記述方法で日付型に自動的に変換してくれるものもある。
また,日付文字列の表現が問題となることもある。古い処理系では明示的に「年」や「月」が入っていると変換できないこともあるし,「01/05」で1月5日を表現しているのか,5月1日を表現しているのかも,処理系によって解釈が異なることがある。
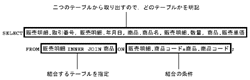
結合もSELECT文で記述
SELECT文は,もう一つの関係演算である「結合」にも使う。やや表現は複雑だが,基本的なSELECT文のFROMの後に結合するテーブルを並べて記述する格好だ(図3[拡大表示])。そして,結合の条件を「ON」以下に記述する。このとき注意したいのが,取り出すフィールドが結合する二つのテーブルのどちらのものなのか,明示的に記述しなければならない点だ。また,結合条件はフィールドまで明示的に記述することにも着目したい。たいていの場合は,同じフィールド名に同じ意味を持たせるので,結合条件がやや冗長に見える。しかし,理論上は別の意味のフィールドの値で結合させることはあり得るので,このような記述方式を採っている。
結合には大きく,INNER JOIN(両者ともに存在している値のレコードのみ)とOUTER JOIN(どちらかでも値が存在しているレコードを採用),LEFT/RIGHT JOIN(片方のレコード集合はすべて採用)がある。現実にはINNER JOINでほぼことは足りる。意味的な関係を満たすのが,INNER JOINだからだ。
集計やソートの記述はやや複雑
ここまではデータベースに対して問い合わせた結果として,レコードが返ってくる場合を見てきた。だがデータベースを操作する場合,単に検索結果のデータが欲しいわけではなく,むしろどのような傾向にあるのか分析したいことはよくある。このような場合に活躍するのが集計機能である。
集計もSELECT文で記述する。ここが少しややこしい感じはあるが,SQLでは問い合わせた結果を得るのにSELECT文を使うことになっている。これまで出てきたクエリーでは,フィールドを返すように指定していたのでレコード集合が結果となっていた。集計ではフィールドを指定していたところで集計関数を記述する。具体的には平均や件数,最大,最小などである。こういった集計関数も処理系によって定義しているものが違うことがあるので注意しておきたい。
集計する際によく使われるのが,グループ化である。例えば支社別の売り上げを求める場合などに使う。支社名でグループ化して,その値別に売り上げを合計すれば,支社別の合計を算出できる。GROUP BYでグループ化したいフィールドを指定する。さらにややこしいことに,条件に合致したレコードに対して集計する場合がある。このとき,集計対象を絞り込むのにWHEREではなく,「HAVING」を使うなど,ややこしい条件が付く。これは評価順位の高低が,キーワードによって決まっているからだ(図4[拡大表示])。
ソートの指定は,評価の順番としては最後になる。「ORDER BY」で指定したフィールドの値順に,検索結果のレコード集合を並べることができる。
例えば,8月分の売り上げの中から,1日の売り上げ合計額が1万円を超えるものの日次売り上げ総額を集計することを考えてみる(リスト1[拡大表示])。最初に発注テーブルと明細テーブルを結合し,その中から8月分のレコードだけを抽出する(WHEREで指定)。さらにその中から注文と商品IDでグループ化して(GROUP BY),合計額が1万円を超えるものだけ取り出す(HAVING)。そこから集計結果を求めて,売上日順に並べ替える(ORDER BY)。このように順番を段階的に考えれば,なんとか理解できないことはない。ただし可読性という点で見ると,決して分かりやすいとは言えない。自然言語風にしたことによる弊害といえなくもない。
「そう言えば,テーブルの定義にもSQLを使いますよね」
「そうだね。SQLはデータベースを操作する場面すべてに使えるから」
「定義と,検索と…」
「データのメンテナンス。更新とか追加とか。データベースの操作は,データを取り出すときだけじゃないということだね」



















































