 「えっとぉ。ここにデータセットを置いて,それからデータベースへのコネクションを作る,と。ふーん。こうやってデータベースにアクセスするのね」
「えっとぉ。ここにデータセットを置いて,それからデータベースへのコネクションを作る,と。ふーん。こうやってデータベースにアクセスするのね」
「段階を置くことによって,データの格納先の違いを隠蔽しているんだよ」
「でも,データベースって,どうして必要なんですか」
「どうしてって…。データ,必要でしょ。取っておかないと,後で困るし」
「だけど,面倒なこともありますよね」
![]() データベースは,大量のデータを管理するのに便利なものだ。検索など自前でプログラムを組むのが難しい処理もこなしてくれる。一方プログラムから見ると,データのハンドリングは必須のものだ。どんなに簡単なプログラムであっても,常に何らかのデータを利用する。プログラムは,何らかのデータ入力(ユーザーが操作した結果発生するイベントもデータと考えられる)があると,それに応じた結果を出力するからだ。
データベースは,大量のデータを管理するのに便利なものだ。検索など自前でプログラムを組むのが難しい処理もこなしてくれる。一方プログラムから見ると,データのハンドリングは必須のものだ。どんなに簡単なプログラムであっても,常に何らかのデータを利用する。プログラムは,何らかのデータ入力(ユーザーが操作した結果発生するイベントもデータと考えられる)があると,それに応じた結果を出力するからだ。
| ||
| ||
| ||
|
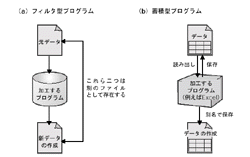
ただし,データの性質が違う。例えばフィルタ型のプログラムは,データはそのプログラムに依存したものではない。テキストデータを加工して,別のテキストデータに変換したりする。またフィルタであれば,入力とは別のファイルを生成するのが通常である。言ってしまえば使い捨て的な動作モデルである。新しく作成したデータを同じプログラムで使えるとは限らない(図1[拡大表示])。一方,蓄積型のプログラムは,作成したデータを何度も利用する。保存するデータは,そのプログラムで利用するためのものである。データベースを利用する可能性があるのは,後者である注1)。
構造化されたデータを集積
もちろん,蓄積型のすべてのプログラムがデータベースを利用するわけではない。例えばワープロの文書ファイル。これを管理するのにデータベースを使うことは少ない注2)。データベースが扱うデータは,構造化されたデータが複数個集積したものである。
では構造化されたデータとはどんなものだろうか。データというのは,元々ある程度構造を持っているのである。単に「1」という数字が存在していても,それが「1月」なのか「1度」なのか,「1番」なのかわからない。そのデータをどう解釈するか(どのような意味を持つのか)を決めているのが構造なのである。データを解釈する構造を決めておくことにより,その数字なり文字列なりがどのような意味を持つかプログラムで理解できるようになるのだ。逆に言えば,蓄積型のプログラムであれば,すべて構造化されたデータを保存したり,読み出したりしているのである。
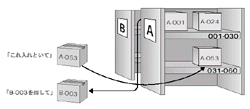
この構造化された一連のデータが複数セットあるとどうなるか。それぞれのセットが一つの単位として取り扱えて,しかもそのセットごとに何らかの処理ができるようになっていなければならない。ここで出てくるのがデータベース管理システム(DBMS)である。構造を持つデータを複数,切り替えて使ったりするためのものである。そのためにDBMSは,(1)データ群の識別,(2)構造単位でデータを取り扱う機能,(3)条件に合致したデータの取り出し,といった機能を備えていなければならない(図2[拡大表示])。
もちろんこういった機能を独自に実装しても構わないが,DBMSを使えば検索が高速であるため大量のデータから条件に合致したデータを取り出しやすい。またデータの一貫性を保証する機構も備えているので,敢えて独自の管理機構を実現する必要もないだろう。実際,同じ構造のデータが複数セットあるという場面を考えると,その数は2個や3個ということは少ない。個人の住所管理程度であっても,100件以下ということはまずない。企業で使うデータとなれば,その数は莫大なものになる。こうなってきたら,独自に実装するというアイデアはほとんど無意味である。
後発のリレーショナル・モデルが主流に
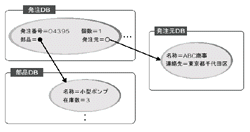
現在でこそ,データベースというとまず表形式のデータを思い浮かべるが,純粋な表形式データによるデータベースは遅れて登場した。当初は「階層型」や「ネットワーク型」と呼ばれるデータベースだった。階層型やネットワーク型はいずれも,データ構造を直接実装に反映させたものである(図3[拡大表示])。つまり,データの参照関係などが,直接埋め込まれた形になっていたのである。
この形態の大きな欠点は,データ構造の変更が難しいこと。実装方式にも依存するが,データ構造が直接データベースに反映されているため,データベース自体に大幅な変更が必要になる。またデータ構造を明確にプログラム中で記述しなければ利用できない。このため,データベースとプログラムの関係が密になりすぎて,データの管理が困難になるという欠点もある注3)。
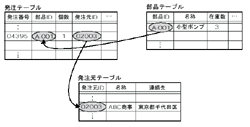
これらの欠点を克服したデータモデルが,リレーショナル・モデルである(図4[拡大表示])。リレーショナル・モデルでは,すべてのデータを表(テーブル)で表現する。そして複数のテーブルの項目を値で関連付けるのが特徴である。値によって結び付けることにより,複数のテーブルの独立性を高め,しかも関連を維持できる。リレーショナル・モデルには,集合に基づく明確な理論的背景があるので,正しい使い方を押さえておくことが重要である。



















































