 |
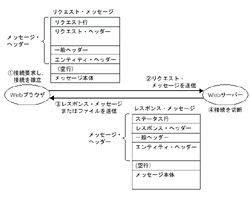
| 図2●HTTPの実態 Webブラウザの一つのリクエストに対し,サーバーは一つのレスポンスを返す。このときやり取りするメッセージの形式が定められている。ここがHTTPの骨子,とも言えよう。Webブラウザが接続を要求し,接続が確立したらリクエスト・メッセージを発行する。サーバーはこのリクエストを受け,適切な反応をレスポンス・メッセージとして返し,接続を終了する。Webブラウザはこの形式に従ってリクエストを作成し,レスポンスを正しく解釈しなければいけない。単純な話,画像データをリクエストして,そのフォーマットが正しく解釈できなければデータは「化けて」しまったことになる。データが正しく送られるかどうかについては,原則としてTCP/IPが責任を負うことになる。 |
リクエスト-レスポンス型の動作
HTTPが実際にどのように通信するかを見ておこう。HTTPの動作は,リクエスト-レスポンス・モデルに基づいている。つまりクライアントが一つのリクエストを発行すると,サーバーが一つのレスポンスを返すという単純な動作形態だ(図2[拡大表示])。クライアントが発行するリクエストも,サーバーが返信するレスポンスも,HTTPで定めたメッセージに従っている。リクエスト・メッセージの先頭行には,サーバーへの処理の依頼内容(リクエスト)を記述する。サーバーはその結果が正しく処理されたか,エラーが起きたかなどを識別するコード(ステータス)を先頭行に記述して返信する。
このとき,1回のリクエストで接続が切断されることに注意されたい。クライアントがリクエストを発行するため,ソケットを接続する。サーバーはレスポンスを返すと,そこで接続を閉じてしまう。これがWebでショッピング・サイトなどを構築するときに,Cookieなど別の仕組みを使ってセッションを維持しなければならない理由である。
クライアントが送信するリクエストには,ファイルを取得するGETのほか,ファイルにデータを渡す「PUT」,サーバーにファイルの削除を依頼する「DELETE」などがある。HTTP 1.1で必須とされるリクエストは8種類しかない。これを見るとHTTPがいかに単純なモデルで動作しているかが分かるだろう。HTTP 1.0になると,GET/PUTのほかに,ヘッダーを取得する「HEAD」の三つしかないのだ。HTTPは元々ファイル転送の仕組みであり,“World Wide Web”の難しい部分はHTMLの解釈に任せてある結果とも考えられる。実際にHTTP 0.9版になるとステータスすら返さない。すぐにファイルを送信するようになっている。
HTTPのレベルでは,むしろエラー・コードの方が複雑である。ほとんどの人が一度は目にした「404 File not found」というのも,HTTPのエラー・メッセージなのである。ただWebブラウザに表示される画面は,Webサーバー側で変更できる。Webサーバーが返したエラーを表示するHTMLを表示することもあるし,会社から利用する場合はProxyサーバーが返したHTML文書を表示したりする。
エラー訂正は下のレベルで
HTTPを見ても分かるように,アプリケーション・レベルのプロトコルの多くはソケットから正しいデータが上がってくることを前提としている。TCP/IPのレベルで,パケットに格納された情報が責任持って送られてくるからだ。イーサネットの段階でCRC(Cyclic Redundancy Check)を使ってエラーを検出している。TCP/IPのレイヤーでは,データを受け取ったら「ACK」を返す。これを一定時間受け取れなかった場合,再送を要求することになる。
CRCでは,送信対象のデータからエラー検出用のデータを算出し,これを元データに付加して送信する。これがデータの指紋のような役割を果たす。受け取った側で同じ計算を実施して,算出した結果が同じであれば正しいデータが送られたと判断する。TCP/IPの場合,エラーがあれば再送を要求する。一度に送受信されるデータの量は,原則として下のレイヤーにいくほど少なくなる。つまり下層で処理すれば,再送するデータ量も少なくなる。そのぶんデータを効率よく,かつ正しく送ることができるわけだ。上位のプロトコルでエラー修正することもなくはないが,効率はよくない。
アプリケーション・レベルでは,「正しくデータが転送されたか」よりも,別のレベルでエラー処理が必要となる。例えばWebブラウザでは,画像ファイルなどが存在しないこともある。この場合は画像の枠だけ表示して,適切にレイアウトしなければならない。また,サーバーが通知するファイルの大きさが,実際に表示する画像の大きさと異なることもある。このときは正しいサイズにレイアウトを変更するといった動作が必要になる。ストレートに処理できる場合よりもむしろ,想定し得るさまざまなエラーをいかに処理するかが,プログラムを作成するうえでの重要なポイントとなる。俗に80:20の法則と呼ばれるものの一つだ。この場合,80%のコードがエラー処理に使われ,本質的な部分の記述は20%にすぎないという説明に使われる注1)。この経験則がどの程度真実かは不明だが,プログラムのかなりのパーセンテージをエラー処理が占めるのは事実である。
ややこしい処理はライブラリに任せる
こういった処理の記述で助かるのが,さまざまなコンポーネントやライブラリである。本当にブラウザをアプリケーションの一部に取り込むのであれば,Internet Explorerを部品として組み込んでしまえばよい。IEはOSに付属する標準コンポーネントなので,OLEによるソフトウェア部品に対応した開発ツールであればどれでも利用できる。またHTMLを表示したいのでなく,データをHTTPで取得したいのであれば,HTTPを処理するコンポーネントを組み込めばよい。.NET FrameworkやJavaを使う場合でも話は同じだ。どちらもHTTPを取り扱うためのクラス・ライブラリが用意してある。ただ同じインターネット標準のプロトコルであっても,NNTPやFTPとなると標準では.NET FrameworkやJavaにはライブラリが存在しない。Java用ならばIBMやSunが公開しているFTPクライアントのライブラリなどを利用することになる。
「うんうん。細かいことはライブラリに任せて,ってことですね」
「特にインターネット経由で外のサーバーと連携する場合は,HTTPを使うことが多いからね」
「SOAPもそうですね。こないだ先輩は,SOAPはRPCだと思えばいいって言ってましたけど,じゃあRPCもソケットを使った通信なんですか」
「そう。RPCはソケットを使って通信してるよ」



















































