![]() インターネットから情報を探し出す第一歩として,誰もが検索サイトを利用する。たいていのユーザにはそれぞれお気に入りの検索サイトがある。しかし,検索結果は違わないことが多い。検索サイトの多くが,バックエンドで同じサーチ・エンジンを使っているからだ。Googleである(図1[拡大表示])。
インターネットから情報を探し出す第一歩として,誰もが検索サイトを利用する。たいていのユーザにはそれぞれお気に入りの検索サイトがある。しかし,検索結果は違わないことが多い。検索サイトの多くが,バックエンドで同じサーチ・エンジンを使っているからだ。Googleである(図1[拡大表示])。
Googleはあまたのサーチ・エンジンを抑え,インターネット検索の世界で一人勝ちの様相を見せている。Yahoo!,Excite,BIGLOBE,@Niftyなど,大手のポータル・サイトやインターネット・サービス・プロバイダが,自前のサーチ・エンジンを捨ててまでGoogleのエンジンを採用している。後発のGoogleは多くの検索サイトを押しのけて現在の地位についた。そして今後は,Googleが追われる番だ。
量から質への転換に成功
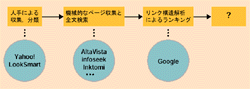
Googleが成功したのはいち早く,量から質への転換を果たしたからだ。インターネットが一般に開放されてから10年余の間に,いくつかのサーチ・エンジンが一時代を築いてきた(図2[拡大表示])。1994年にサービスを開始したカテゴリ検索のYahoo!は,人手で情報を整理して登録する手法を採っていた。その翌年には,全文検索に基づくサーチ・エンジンAltaVistaが登場した。機械的に大量のデータを集め,さらにその中のすべての文字列を検索対象にする。世界中に散らばる膨大なデータの中から,多くの文書を見つけられるようになった。
データの「量」が確保できたら,次は「質」が求められる。ここにうまくはまったのがGoogleだ。Googleの成功の理由は,質の高い情報を優先的に表示し,検索精度を高めたところにある注1)。
信頼性の高いページを上位に出す
検索の基本的な処理を見ると,Googleと他の多くのサーチ・エンジンに大きな違いはない注2)。インターネット上の文書をかき集めて,インデクスを作って検索する(別掲記事「高速検索の理由はインデクスにあり」参照)。Googleは検索結果を表示する順序を工夫して,検索の質を上げた。
単に検索語を含んでいるだけのページは,ほとんどの場合無数にある。その中でいかに妥当なものを上位に表示するか。これがサーチ・エンジンの腕の見せ所となる。
|
|
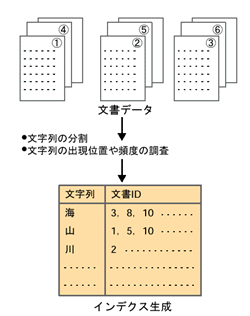
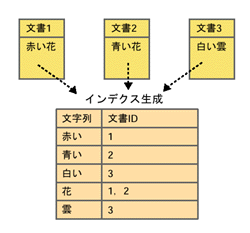
高速検索の理由はインデクスにありインターネットのサーチ・エンジンは,インターネットにある膨大な量のデータに対して一瞬にして検索を済ませ,結果を返してくれる。これは,サーチ・エンジンが事前にインデクスという検索用のデータを作っているからである(図A[拡大表示])。辞書で単語を調べるとき,索引(インデクス)を見てページを知ると同じ仕組みだ。 インデクスを作るには,まず文書データを収集しなければならない。データ収集のためのプログラムが,リンク情報などを頼りにサーバを巡回してデータを集める。この処理をクローリング(crawling)と言い,処理を実行するプログラムをクローラ,またはロボットなどと呼ぶ。Googleでは,複数のクローラを使ってデータを収集し,一つひとつの文書にID番号をつけている。同社によれば,2002年9月現在でクローリングの対象は24億ページにのぼるという。 インデクスは集まったデータを使って作成する。サーチ・エンジンにおけるインデクスは,文書を構成する文字列から,検索するための情報を抽出したものである。最も基本的なインデクスの構造は,文字列と,それを含む文書との対応表の形を取る(図B[拡大表示])。実際にはこれ以外にも,その文字列の出現位置などの情報もインデクスに格納されることが多い。またどの単位で文字列を区切るかには,いくつかの手法がある(詳しくは第2部)。 検索処理はインデクスを参照するだけで,元のデータは使わない。検索語として入力された語を同じように適切な単位の文字列に区切り,インデクスを使ってそれを含む文書を探す。たとえば,図Bのようなインデクスがある状態で「花」という文字列で検索した。インデクスを参照した結果,文書IDが1と2の文書を表示することになるのである。 インデクスを参照するだけで,その都度Webページを探しに行くわけではない。だから膨大なデータでも一瞬で検索できる注A)。ただしこの方法では,Webページを更新しても,それがサーチ・エンジンによって収集され,インデクス化されるまで検索結果に反映されないという現象が起こる。サーチ・エンジンが表示したページが存在しないことがあるのはこのためだ。
|