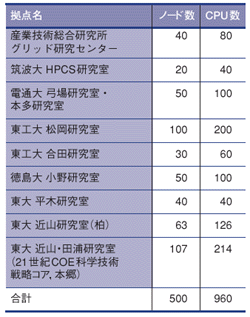
![]()
| ||
| ||
|
 印の6カ所をチェックするだけで済む。周りのピクセル(左と上)を調べる方法だと,16カ所のチェックが必要なので,処理を大幅に減らすことができる。
印の6カ所をチェックするだけで済む。周りのピクセル(左と上)を調べる方法だと,16カ所のチェックが必要なので,処理を大幅に減らすことができる。課題は一見単純だが奥深い
実行委が設定した課題は,平面上に配置された「物体」を数える早さを競うというもの。
図1[拡大表示] のようにピクセルがXY方向に並んだ平面を考え,物体が占める場所を1,ない場所は0とする(図ではオレンジに塗った部分が1)。縦横に隣り合ったピクセルが1なら同じ物体が連続しているとし,対角に1が並ぶ場合はつながっていないとした。物体の形としてはドーナツ型のようなものを含む。入れ子になっている場合もある。
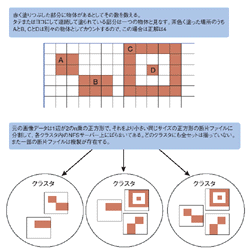
この物体を数える作業は1台のコンピュータでもできるが,グリッドのパワーを使って数えようというのだ。それぞれ同じ大きさの正方形の断片に切り刻み,グリッド内の各ノードに数えさせる。
各断片を示すデータ・ファイルを9カ所のクラスタ上のNFSサーバーに分散配置した。またサイズを小さくするためにランレングス圧縮(例えば「AAABB BBCCCC」は「A3B4C4」というように,同じ値が続く場合はその値と個数で示す)をかけた。各クラスタには全ファイルではなくサブセットを置いて,必ず他のクラスタとの通信が必要になるようにした。また,断片ファイルの一部は複数のクラスタに複製を置いた。断片ファイルの分割の仕方で初級と上級の2クラスを設けた。初級では一つの物体が複数の断片ファイルに分割されていることがない。上級は分割されていることがある(ただしまたがるとしても2ファイルまで)。
実行委員長の田浦健次朗東大助教授によれば「グリッドの効果があり,通信量がそこそこあり,敷居が低いこと」を条件に問題を選んだが,選手たちの感想は「工夫するポイントがたくさんあって奥深い」というものだった。
物体の数え方が高速化のポイント
では選手たちはどんな工夫をしたか。大きく影響したのは数え方だ。
断片の中の物体を数えるには,先頭(左上)から順にピクセルの値を調べていくしかなさそうだ。あるピクセルが1なら,すでにチェックしたはずの,上か左のピクセルを確かめる。1であれば同じ物体が連続していることになるが,何もなければ新しい物体の端っこということになるのでカウントを増やす。次に1ピクセル移動して同じ動作を繰り返し,最後まで見れば,すべての物体が数えられる。
ここで上位入賞者は,元のデータがランレングス圧縮されていることに注目した。圧縮がかかっているのなら,その部分は連続していることになる(もちろん断片の端で折り返している場合もあるのでそのチェックが必要だ)。
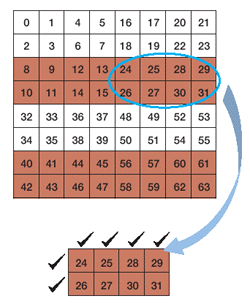
例えば断片のサイズが8ピクセル×8ピクセルで,今注目しているピクセルが24番目(3行目の5列目)に当たるとする。そこから8ピクセル分が圧縮されているなら,図2[拡大表示] のように6カ所(下の図でチ ェックマークがついているところ)を調べれば他の物体と連続しているかしていないかが分かる。上級部門の優勝者である東大大学院の鴨志田良和氏(当時修士2年)によれば,「圧縮を考慮しないときよりも15倍以上早くなった」という。
もう一つはファイルサーバーのキャッシュの使い方だ。NFSサーバーから断片ファイルを読み込む場合,すでにキャッシュにあるファイルなら高速に読み出せる。特にアクセスが集中する場合には,キャッシュにヒットするかどうかは大きな差になる。そこで上位入賞者は各ノードが常に同じファイルを計算対象とするよう固定的に割り当てた。「90秒近くかかった読み出しが数秒になることもあった」(鴨志田氏)そうだ。
性能が違うノードにうまく負荷配分
参加者のプログラムの中でも,抜きんでたプログラムは二つ。鴨志田氏と,やはり東大の山崎孝裕氏(当時学部4年)のプログラムである。2人の勝敗を分けたのは何か。
一つは山崎氏のプログラムでのキャッシュの使い方にあった。各ノードがたまに違うファイルを計算対象にする要素が残っていた。
さらに鴨志田氏のプログラムでは,各ノードの性能差を考慮して負荷を調整していた。グリッド環境では性能の違う異機種が混在する。そこで何も考えずに全ノードに同じ数の断片ファイルを処理させると,先に処理を終えたノードは無駄な時間を過ごすことになる。これを防ぐために,未処理のファイルを次々に処理させるようにすると,今度は各ノードが処理するファイルが一意に決まらず,キャッシュを有効に使えなくなる。つまり,どのノードにいくつ断片ファイルを処理させるかを実行前に計算する必要がある。
鴨志田氏は各クラスタの計算能力をノードの数と各ノードのCPUの動作周波数,CPUの搭載数から推定して,それぞれのクラスタで処理する断片ファイルの数を決めた。さらにクラスタ内では動作周波数を基に速いノードに多くファイルを配分した。
こうした工夫のかいもあって,完成したプログラムはほんの数秒の差で栄冠を得た。



















































