![]()
| ||
| ||
| ||
|

東京大学大学院情報理工学系研究科の米澤明憲教授の研究室では,この問題を解決するC言語コンパイラ「VITC(Vulnerability and Intrusion Tolerant Compilation)」を開発中だ。今年度中のプロトタイプ完成を目指す。
別領域にバッファを確保
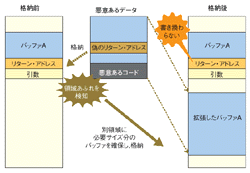
バッファ・オーバーフローとは,スタックに確保されたデータの領域(バッファ)を越えてデータを書き換えてしまうことである(図1[拡大表示])。スタックには,関数を呼び出したときに,その処理が終了したあとプログラムが戻る位置を示すリターン・アドレスが存在する。ここの内容を書き換え,戻る場所を不正な処理の先頭にしてしまう。こうして悪意あるプログラムを実行させるのがバッファ・オーバーフローを利用した攻撃だ。
この攻撃を防ぐための策としてはまず,バッファの領域あふれを検知するコードをコンパイラが挿入する方法がある。米Immunix社の「StackGuard」などが知られている。また2004年には,スタック領域におけるコード実行を抑制する「NXビット」を導入したマイクロプロセッサも登場した。
これらはいずれも,不正なコードによってバッファの状態が書き換えられた後に攻撃を検知する。したがって正しい状態に戻ることはできず,プログラムは停止してしまう。VITCは,バッファ・オーバーフローを事前に検知するのが特徴だ。
バッファ・オーバーフローの検知には,米澤研究室がこれまで開発してきたCコンパイラ「Fail-Safe C」の仕組みを利用する。ポインタは単なるアドレスではなく,バッファの先頭位置と,そこを基準にした相対アドレス(オフセット)を持つ。バッファもデータだけでなく,格納できるデータの型や,データの個数の情報を保持する。バッファにデータを格納する前に,オフセットや格納できるデータの個数などの情報を利用して領域あふれが起こらないかチェックする。
領域のあふれを検知したら,VITCではメモリー空間上の別の場所に,十分なサイズのバッファを確保する。そして,ここにデータを格納する(図2[拡大表示])。プログラム中で元のバッファのアドレスを参照する個所は,別の場所に確保したバッファを参照するようにポインタを書き換える。
こうすれば,リターン・アドレスは書き換えられない。関数の終了後は,通常通りその関数を呼び出した個所に戻る。バッファ・オーバーフローを防ぎながら,プログラムの実行を続けられる。
データの漏洩を防ぐ
VITCにはもう一つの目標がある。ソースコードを解析して,機密データの漏洩を防ぐことだ。前述の仕組みでプログラムの停止を防いだとしても,例えばパスワード・チェックを怠るなどプログラムの動きそのものに欠陥があっては元も子もない。このようなミスを自動的に検知するのは難しいが「機密データかそうでないか程度は判断できる。それが外部に出るのを確実に防げば,機密漏洩は発生しない」(東京大学大学院情報理工学系研究科の古瀬淳研究員)。
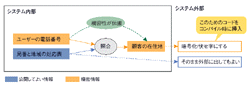
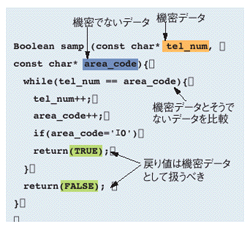
機密データの漏洩防止には,情報流解析という手法を使う。プログラムを解析して,プログラム中のデータの関係や変遷を導き出すものだ(図3[拡大表示])。プログラムで扱っているデータのうち,個人情報など機密データをあらかじめ指定しておくと,それを基にプログラム中のどのデータが機密データにあたるかを解析する(リスト[拡大表示])。こうしたデータをそのままファイルに書き込んだり,ネットワーク経由で他のシステムに送信するプログラムが記述されていた場合,情報漏洩が起こる危険性があると判断できる。
VITCは問題を回避するためのソースコードをコンパイル時に自動的に挿入する。例えば表示の際に機密データを伏せ字にしたり,暗号化するためのコードの挿入を考えているという。
またソースコード解析では機密データと判断されなかったものも,プログラムが正常な状態で実行されていないときは機密データになる可能性がある。例えば前述のバッファ・オーバーフローを検知した場合である。拡張したバッファ領域を確保してプログラムを続行していると,プログラム作成者の意図通りに処理が進まない可能性がある。バッファに入っているデータを暗号化し,その結果をシステム外に出力するプログラムがあるとする。このときバッファのデータサイズ分しか暗号化しないようなコードが書かれていると,データサイズを超えた部分のデータは暗号化されない。そこで,拡張バッファを利用して処理を続行している場合には,その処理に影響を受けている出力データに伏せ字や暗号化を施す,という処理を挿入する。
すべては自動化できない
ただ,このような解析では,処理の内容によっては機密データを出力してよい場合を判別できない。例えば認証済みのユーザーに対しては個人情報の出力を許可してもよいはずだ。だがどのコードが認証処理に該当し,その処理の結果どのような値が得られれば認証に成功したのかということは,静的解析だけでは判断できない。「このような場合には,今のところユーザーに手動でプログラムを改変してもらうしかない。その手間をどの程度減らせるかが今後の大きな課題だ」(古瀬氏)。



















































