![]() インターネットの膨大な情報の中から自分が求めるものを探すとき,誰しもまずGoogleなどの検索エンジンを使うだろう。この検索エンジンは,文書中のすべての文字列を検索対象にし,入力された検索語を含む文書を返す。これを全文検索という。
インターネットの膨大な情報の中から自分が求めるものを探すとき,誰しもまずGoogleなどの検索エンジンを使うだろう。この検索エンジンは,文書中のすべての文字列を検索対象にし,入力された検索語を含む文書を返す。これを全文検索という。
全文検索では,まず検索対象となる文書を短い文字列に区切る。そして,どの文書が区切った文字列を含んでいるかを対応付けた表(インデックス)を作成する。検索文が入力されると,こちらも同じように短く区切り,インデックスと比較する。つまり,両者が同じ文字列を含んでいても,その区切りが異なると正しく検索できない。
実はここに,長きにわたる論争があった。文字の区切り方に二つの有力な手法があるのだ。しかし2002年12月,この論争に決着がついたようだ。国立情報学研究所が主催する検索エンジンの評価型国際会議NTCIR(NII Test Collection for Information Retrieval Systems:エンティサイル)の第3回の成果報告で,片方の有力な推進者が転向したのである。
検索文は形態素解析で分解すべし
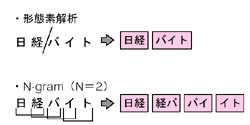 |
| 図1●形態素解析とN-gramの違い 形態素解析は,辞書を使って意味のある単語単位に分解する。N-gramは,意味は考慮せず決められた長さで文字列を区切る。 |
NTCIRは1998年に始まった。複数の参加グループが同じ課題に取り組み,結果を評価することで検索技術の発展を促進するのが目的だ。3回目となった今回は,2001年8月から2002年10月にわたって開催された。9カ国から企業や大学など65の研究グループが参加した。
二つの文字の区切り方とは,形態素解析とN文字インデックス(N-gram)である(図1[拡大表示])。形態素解析は,辞書を使って文字列を意味を持つ最小の単位(形態素)に分解する処理である。これに対してN-gramは,文字の意味は考慮せずに一定の長さNで文章を区切る。
形態素解析で文字を区切ると,意味のある単語に基づいて検索できる。部分的に文字が一致しているだけの意味のない文字列を拾わないため,検索ノイズが減る。その代わり,単語が辞書にない場合は適切に区切れず,検索漏れが発生する可能性がある。逆にN-gramなら検索漏れは起こらないが,検索ノイズが増えてしまう。
前回のNTCIRでも,この二つの手法をめぐって参加グループの意見が分かれた。実際両者の検索精度はほぼ拮抗しており,優劣はつけ難かった。ところが今回,前回N-gramを強力に推薦した米カリフォルニア大学バークレー校が,形態素解析を使って検索文を単語単位に区切る方が有効だと報告したのだ。「NTCIRで常に上位に付けるグループの報告だけに,信頼度は高い。単語単位で文字列を区切る方法が有効だと結論付けていいだろう」(国立情報学研究所の神門典子助教授)。ただし検索対象となるデータに関しては,検索漏れを防ぐためにN-gramで区切る方がよい場合もあるという。
 |
| 表●第3回のNTCIRで設定された課題 五つの部門が設けられた。特許検索,Web検索,質問応答の三つが,第3回から新たに加わった。 |
検索結果からの情報抽出も重要
このほかのNTCIRの成果も見ておこう。今回のNTCIRで用意された課題は5種類(表[拡大表示])。参加グループには,課題ごとに定められた検索用のデータと検索文が配られる(図2)。日本語のデータが中心だ。
参加グループは,配られた課題を解くための検索エンジンを開発し,その結果を提出する。NTCIRはそれぞれの結果を評価して順位付けをする。
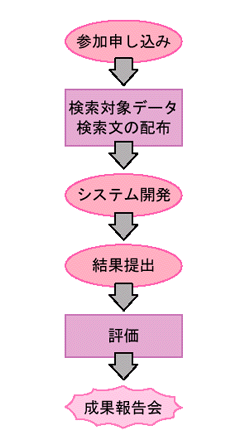 |
| 図2●NTCIRの流れ 参加チームには,検索対象となるデータと検索文が配布される。これを基にシステム開発をし,結果を提出する。これがNTCIRによって評価される。成果は成果報告書としてまとめられ,成果報告会も開かれる。 |
最も参加グループが多かったのが言語横断検索だ。検索文とは異なる言語で書かれた文書も検索対象にする技術である。特に米国では,国防上の観点からこの分野の研究が重視されている。2001年9月11日の同時多発テロ事件のあとは,英語でアラビア語の情報を検索する技術に力が入れられているという。前述のカリフォルニア大学バークレー校の発表もこの課題だ。
検索以外の技術が必要とされる課題もある。「検索した文書を一覧表示するだけでは不親切。そこから有益な情報を取り出す技術も重要」(神門助教授)だからだ。ここに主眼を置いた課題が質問応答である。質問に答えるための知識データとして利用するのは2年分の新聞記事。まず検索文が何を求めているかを解析し,それに関連する新聞記事を検索する。次に,記事中から検索文に対する答えをピンポイントで抽出して提示する。例えば「千葉県の県庁所在地は何市か」という質問文に対して,答えそのものの「千葉市」を返す技術である。トップのチームは200問中,約60%の正解を導き出したという。
新たな検索手法の提案も
特許検索の課題は今回初めて登場した課題だ。新聞記事を基に,それに関連する特許情報を検索するという,現実にありそうな状況を想定している。
特許検索では,検索語の元データとなる検索文として新聞記事,検索対象として実際の特許情報が使われる。この二つのデータは,言葉の使われ方が大きく異なる。この違いを吸収するために,リコーは検索語の選び方に関する新たな手法を提案した。
検索結果の上位には,基本的に検索語を多く含む文書がくる。ただしその際に,検索語ごとに持たせる重みを変えるのが一般的だ。このときその語が他の文書にも頻繁に出てくる場合は重みを下げ,出てこない場合は上げる。他の文書にあまり出てこない単語はそれだけ特徴的,つまり重要であるという考えに基づいている。
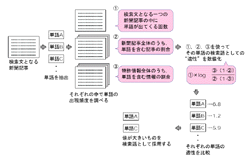 |
| 図3●リコーが開発した特許検索技術 検索文となる新聞記事から単語を抽出したら,3種類のデータに対してその出現頻度を調べる。その値を使って,単語が検索語としてどのくらい適切かを数値化する。数値が大きいものを検索語として選ぶ。数値化の手法は複数試したが,今回は図中の方法が最も良かったという。 |
しかし特許検索にこの考えをそのまま適用すると,予想外のものが上位に来てしまう。例えば新聞記事には「社長」という単語が多く含まれる。検索文は新聞記事なので,これが検索語に入る可能性は高い。しかし検索対象となる特許情報には「社長」はほとんど出てこないため,高い重みがつけられてしまう。結果として実際はあまり意味のない「社長」が特徴的な語だと判断され,それを含む文書が上位に来る。
そこで,検索文に登場する頻度と検索対象に登場する頻度に大きな差がある単語を検索語にしないよう,検索式を見直して精度を上げた(図3[拡大表示])。
この考え方は,特許検索以外にも応用できる可能性がある。例えば,検索対象となるデータと自分の言葉の使い方が違う場合,その差を吸収するのに使える。ただしその方式から明らかなように,検索文中の言葉の登場頻度があらかじめわかっていなければならない。



















































