矢沢 久雄
![]() 今回は,Windowsアプリケーションを作成する場合に,文字コードをどのように取り扱えばよいかを説明します。Windowsアプリケーションは様々な開発ツールを使って作成できますが,ここでは主にVisual Basicを使います。Windowsは,現在,シフトJISコードからUnicodeへの転換期にありますが,プログラミングにも,それが如実に現れています。Visual BasicにもWindows自体にも,シフトJISコードとUnicodeの両方を取り扱う仕組みが提供されているのです。
今回は,Windowsアプリケーションを作成する場合に,文字コードをどのように取り扱えばよいかを説明します。Windowsアプリケーションは様々な開発ツールを使って作成できますが,ここでは主にVisual Basicを使います。Windowsは,現在,シフトJISコードからUnicodeへの転換期にありますが,プログラミングにも,それが如実に現れています。Visual BasicにもWindows自体にも,シフトJISコードとUnicodeの両方を取り扱う仕組みが提供されているのです。
●Unicodeはプログラムで処理しやすい
WindowsがシフトJISコードからUnicodeへの転換期にあるとは言っても,Windowsにおけるファイルの保存形式の主流は依然としてシフトJISコードのままです。もしもUnicodeでファイルを保存してしまうと,それを読み出せないアプリケーションが多いからです。なんとかUnicodeへの転換を促進させたいものですね。
|
|
| 図1●ファイルはシフトJISコード,プログラムの中ではUnicode |
なぜVisual Basicは,Unicodeを採用したのでしょう? Unicodeを流行らせるためだと思われるかもしれませんが,そうではありません。シフトJISよりUnicodeの方がプログラムの処理が簡単になるからです。例えば,「123漢字ABC」という文字列の文字数を求めるとしましょう。シフトJISコードのままで処理する場合は,「漢」と「字」の部分が漢字であることを判別するプログラムが必要になります。この文字列は,シフトJISコードで10バイトになりますが,数字と英字は1文字1バイト,漢字は1文字2バイトなので,全体で8文字になります。
同じ文字列をUnicodeで処理してみましょう。Unicode(UTF-16)では,数字,英字,漢字にかかわりなく,1文字は2バイトです。したがって,「123漢字ABC」という文字列は,16バイトになります。16バイトなら,16÷2=8文字と簡単に計算できるのです。ただし現在,Unicodeは1文字に4バイトを割り当てる仕組みを導入する方向に向かっています。将来,この仕組みが使われ始めると,1文字を2バイトで表すことの便利さは薄れてしまう可能性があります。
●文字列の長さとバイト数を求めてみよう
Visual Basicが提供している命令の中で,文字列の文字数(長さ)を求めるのはLen関数です。Len関数は,パラメータに与えられた文字列をUnicodeとみなして,その文字数を返します。LenB関数という命令もあります。LenB関数は,文字列のバイト数を返すものです。
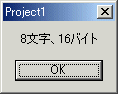
|
| 図2●リスト1の実行結果 |
●文字と文字コードの変換
Visual Basicで,パラメータに与えられた文字の文字コードを返す命令は,Asc関数です。文字コードに対応する文字を返すのは,Chr関数です。これらの関数を使えば,文字と文字コードを相互に変換するアプリケーションが作成できます。ところで,Asc関数が返す文字コードや,Chr関数のパラメータに与える文字コードの種類は,何だと思われますか? Visual Basicは,内部的にUnicodeを採用しているので,Unicodeとすべきでしょう。ところが,実際には,どちらもシフトJISコードなのです。このあたりが少々ややこしいかもしれません。

|
| 図3●リスト2の実行結果 |
メモリー上ではUnicodeで文字を処理しているVisual Basicであっても,プログラマが文字コードを指定する場合にシフトJISコードが使われるのはなぜでしょう? これは,あくまで筆者の推測ですが,ファイルの保存形式の主流がシフトJISであるからには,プログラマが慣れ親しんでいる文字コードは,シフトJISコードであると(Visual Basicの開発者が)考えたからでしょう。
ただし,Visual Basicは,Unicode版のAsc関数やChr関数として,AscW関数とChrW関数も提供しています。これらの関数名の末尾のWは,Wide文字(2バイト文字)を表しています。Unicodeが十分に普及すれば,Asc関数やChr関数の方がUnicode用で,シフトJISコード用のAscA関数やCharA関数(末尾のAは,ANSIの頭文字を表します)が提供されるようになるかもしれませんね。
●Win32 APIもシフトJISコードとUnicodeの両方に対応している
Visual Basicに限らず,Visual C++,Delphi,JBuilderなど,どのような開発ツールで作成されているとしても,Windowsアプリケーションである以上は,最終的に必ずWin32 APIを呼び出すことになります。Win32 APIとは,WindowsがOSとしてアプリケーションに提供するシステム・コールのことです。APIは,Application Programming Interfaceの略です。Win32 APIの実体は,様々な機能を持つ関数が収録されたDLLファイルとなっています。
Win32 APIの中には,文字列を取り扱う関数もあります。例えば,TextOut関数は,画面に文字列を表示します。それでは,TextOut関数は,Unicode用なのでしょうか? それともシフトJISコード用なのでしょうか? ヒントは「Windows 95/98/Meは,シフトJISコードを採用したOSであり,Windows NT/2000は,Unicodeを採用したOSである」です…。

|
| 図4●Win32 APIには,シフトJISコード用とUnicode用の関数がある |
なお,TextOutW関数の末尾のWはWide文字を表し,TextOutA関数の末尾のAはANSIを表します。アメリカ生まれのWindowsでは,文字コードはANSI(ASCIIを制定したのがANSIなので,ANSIはASCIIを意味します)からUnicodeへの転換期なのです。
●新しいプログラミング言語は,Unicodeを採用している
Visual Basicの話ばかりしてきましたので,他のプログラミング言語にも目を向けてみましょう。皆さんに知っていただきたいことは,新しいプログラミング言語では,続々とUnicodeが採用されているということです。その好例として,「C言語一族」のプログラミング言語が挙げられます。「C言語一族」のプログラミング言語とは,C言語,C++,Java,C#のことです。
1975年生まれのC言語では,文字をcharというデータ型で表すようになっています。charには,1バイトのデータを格納できます。C言語が登場したときには,ASCIIしかなかったので,これで問題ありませんでした。
1980年生まれのC++は,C言語にオブジェクト指向プログラミングの機能を追加したものです。C++にも1バイトのchar型がありますが,それに加えて2バイトのwchar_t型もあります。1バイト文字と2バイト文字が混在する時代になったのです。Windows用のC++であるVisual C++には,TCHAR型というものもあります。TCHAR型は,Unicode環境と指定した場合,wchar_t型と同じものです。
1995年生まれのJavaは,C++をベースに開発されたインターネット・プログラミングのためのプログラミング言語です。Javaにもchar型がありますが,2バイトのデータを格納するものとなっています。Javaは,内部的にUnicodeで文字を処理しているからです。インターネットとともにUnicode時代が到来したのです。
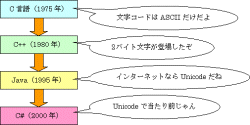
|
| 図5●C言語一族に見る文字コードの変遷 |
この講座の読者の中には,プログラミング経験のない方もいることと思いますが,文字コードの違いがプログラムに大きな影響を与えることをご理解いただけたことと思います。
次回は,文字コードのダンプ・リストを見たり,文字コードを変換したり,機種依存文字をチェックしてくれる便利なフリーウエアの数々を紹介します。お楽しみに!



















































