矢沢 久雄
![]() コンピュータの世界には,様々な文字コード体系が存在しますが,Windowsユーザーが最低限知っておきたいものは,ASCII,JISコード,シフトJISコード,Unicode,EUCの5つでしょう。特にASCIIは,文字コードの元祖とも呼べるほど重要なものです。そのほかの大部分の文字コードは,ASCIIを基にして作られたと言っても過言ではありません。今回は,ASCIIの仕組みと特徴,および文字コードがディスプレイやプリンタに表示,印字されるしくみを説明します。
コンピュータの世界には,様々な文字コード体系が存在しますが,Windowsユーザーが最低限知っておきたいものは,ASCII,JISコード,シフトJISコード,Unicode,EUCの5つでしょう。特にASCIIは,文字コードの元祖とも呼べるほど重要なものです。そのほかの大部分の文字コードは,ASCIIを基にして作られたと言っても過言ではありません。今回は,ASCIIの仕組みと特徴,および文字コードがディスプレイやプリンタに表示,印字されるしくみを説明します。
●ASCII誕生の経緯
そもそも,なぜ文字コードなどというものが必要だったのでしょう? もちろん,コンピュータで文字を処理するためです。ただし,文字コードが必要な理由は,もう一つあります。それは,異なる機種のコンピュータで,文書データを交換するためです。
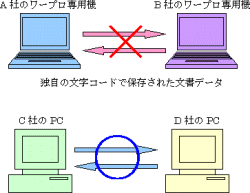
文書データと聞くと,ワープロを想像されることでしょう。昔のワープロ専用機では,それぞれ独自の文字コードが使われていました。「OASYS」「書院」「文豪」といったメーカーの異なる日本語ワープロ専用機では,使われる文字コードがそれぞれ異なっていたのです。これでは,相互に文書データを交換できませんが,あくまでも文書データを印刷することが最終目的であるワープロにとって,文書データの交換はあまり重要ではありませんでした。最近のワープロ専用機には,文書データを交換する機能を持つものが多くあります)。
|
| 図1●統一的なASCIIなら文書データを交換できる |
ASCIIは,American Standard Code for Information Interchange(情報交換のための米国標準コード)の略称です。ASCIIという名前の中に,Information Interchange(情報交換)という言葉が含まれていることから,統一的な文字コード制定の目的が,文書データの交換であったことがわかります(図1[拡大表示])。
●ASCIIの文字コード表
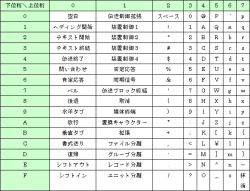
|
| 表1●ASCIIの文字コード表 |
●制御コードは文字列出力装置を制御する
ASCIIの文字コードの中で,00H~1FHと7FHは,文字としては表示しない機能を表すものです。これらを「制御コード」と総称します。制御コードは,コンピュータに接続された文字列出力装置を制御します。文字列出力装置と言うと大げさですが,早い話が,ディスプレイやプリンタなどのことです。例えば,テキスト・エディタで文書ファイルを作成中に[Enter]キーを押したとしましょう。これによって,次の文字の入力位置が改行され,カーソル(Windowsではカーソルのことをキャレットと呼ぶこともあります)が次の行の左端に移動します。これは,ディスプレイという文字列出力装置を,[Enter]キーの文字コードによって制御したことに他なりません。[TAB]キーを押して字下げした場合に,文字の入力位置が水平方向に移動するもの,文字コードによる文字列出力装置の制御です。ディプレイと同様に,プリンタでも,制御コードによって文字の印字位置を制御します。
テキスト・エディタを操作中は,文字の表示位置の移動などを実現する制御コードであっても,文書をファイルに保存すれば,制御コードの数値が記録されます。[TAB]キーは,09Hという文字コードで記録します。[Enter]キーは,0DH(復帰)と0AH(改行)のペアで記録します(これはWindowsの場合です。UNIXでは0AHだけになります)。
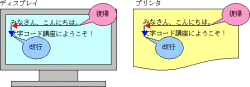
|
| 図2●0DHで復帰し,0AHで改行する |
●おぼえておくべき文字コードの値
コンピュータに関わっている人なら,ASCIIのコード表は暗記するべきでしょう。ただし,すべてを暗記する必要はありません。制御コードの中では,改行(0AH)と復帰(0DH)だけを覚えれば十分です。これらは,文書ファイルにおいて行末の区切りとなるからです。文字を表すコードの中では,スペース(20H),0(30H),A(41H),a(61H)だけを覚えれば十分です。スペースは,英単語の区切りとなります。ASCIIでは,0~9,A~Z,a~zが連続した値の文字コードとなっています。0,A,aの文字コードを覚えておけば,5なら30H+5H=35H,Gなら41H+6H=47H(指折り数えてAの6個先なので),pなら(指折り数えてaの15個先なので)61H+FH=70Hであることがわかります。どうです,簡単でしょう!

|
| 図3●文字コードをおぼえればダンプ・リストが読める |
●ASCIIコードに半角カタカナを追加したJIS X 0201
ご存知のことと思いますが,8ビットのPCが登場したときから現在の32ビットPCに至るまで,ほとんどのプロセッサは,8ビットを基本単位として処理を行っています(32ビット・プロセッサなら32ビットを同時に処理できます)。メモリーやディスク媒体に記録するデータの基本単位も8ビットです。ASCIIは,英語の文書のために作られた文字コードなので,7ビットを使った128通り(27=128)の文字だけで十分でしたが,実際には最上位ビットを0にした8ビットで取り扱われています。これでは,ちょっともったいない気がしますね。

|
| 表2●JIS X 0201の文字コード表 |
表2[拡大表示]は,JIS X 0201の文字コード表です。表の左半分すなわち文字コード00H~7FHまでに割り当てられている文字は,基本的に(05Hと7EH以外)ACSIIと同じです(ピンクの領域)。表の右半分の一部に半角カタカナと句読点などが割り当てられています(水色の領域)。グレーの領域は,未使用であり,文字が割り当てられていません。
ただし,JIS X 0201の半角カタカナの文字コードをおぼえる必要はありません。半角カタカナは,Webページやメールで文字化けの原因となるので,嫌われる存在となっているため,使われなくなってきているからです。8ビットを使って,ASCII+半角カタカナを表すコード体系が存在することだけを知っておいてください。
●文字が表示される仕組み

|
| 図4●キャラクタ・ジェネレータは,文字のフォントを記録したROMである |
ASCIIの128種類(制御コードを除くので,実際には,79種類)の文字のフォントを保存するためには,8バイト/文字×128文字=1024バイト=1Kバイト(K=1024とします)の容量が必要となります。JIS X 0201の256種類の文字なら,ASCIIの2倍の2Kバイトとなります。それほど大きな容量ではないので,ハードウエア的に文字のフォントを記録することは容易です。ただし,横8ビット×縦8ビットの点の集合で表されたフォントでは,見た目に貧弱であり,複雑な形状の文字を表すことができません。
キャラクタ・ジェネレータが使われていたのは,パソコンのOSとしてMS-DOSを使っていた時代のことです。Windowsでは,キャラクタ・ジェネレータは使わず,OSがフォント・ファイルから文字の形状を取得するようになっています。特にTrueTypeと呼ぶフォント・ファイル(現在はTrueTypeが主流です)には,点の集合ではなく,滑らかなベクトル情報として文字の形状が記録されています。文字の形状は,ディスプレイ・コントローラと呼ぶ装置に装備した数MBの容量を持つメモリー上に細かな点の集合として表され,それがディスプレイに転送されます。プリンタの場合は,大容量のROMにフォント・ファイルの情報を記録しているか,Windowsからグラフィックス・データとして文字の形状を送ってもらうようになっています。
もしも,キャラクタ・ジェネレータに記録された文字のフォントを見てみたいなら,パソコンのBIOSセットアップ画面を見てください。BIOSセットアップ画面には,PCに一切のソフトウエアがインストールされていない状態でも文字が表示されます。これらの文字のフォントは,キャラクタ・ジェネレータから取得したものだからです。
何事にも言える事ですが,基本をマスターすることは,とても重要なことです。基本がわかれば,応用もできます。新しい技術も容易に理解できます。ASCIIの知識は,文字コードの基本となるものです。今後の連載の中で,様々な文字コードに触れることになりますが,ASCIIと比較すれば,その仕組みや特徴を理解できるはずです。「ASCIIなんて昔の文字コードだ」などと思うのは間違いです。ASCIIは,今でも現役バリバリで使われ続けています。
次回は,JISコード,シフトJISコード,Unicode,EUCコードを説明します。お楽しみに!



















































