矢沢久雄
●テーブル間の関連性の設定
テーブルを分割したら,テーブル間の関連性(リレーション)を設定しなければなりません。これは,たとえば「井上太郎」が「日経BP社」に勤務していることを特定できるようにすることです。そのためには,2つのテーブルを関連付けるための新たなフィールドが必要となります。このフィールドを「キー(主キーまたは外部キー)」と呼びます。
主キーとは,テーブル内のレコードを一意的に識別するためのフィールドです。世の中には,同姓同名の人物がいたり,同名の会社があるかもしれませんが,主キーの値が異なれば,異なる人物や会社であると識別できます。個人情報テーブルに「個人ID」というフィールドを追加し,会社情報テーブルに「会社ID」というフィールドを追加しましょう(図1)。これらのフィールドが主キーとなります。
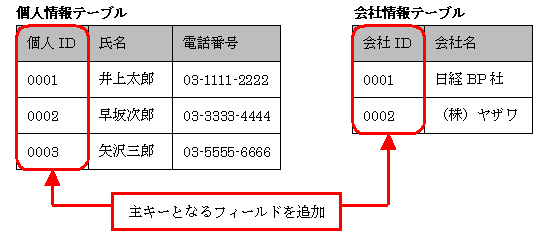 |
主キーには,ユニークな(ほかと重複しない)値を格納します。「個人ID」が0001なら「井上太郎」,「会社ID」が0001なら「日経BP社」であることが識別できます。もしも,「個人ID」が1234の「井上太郎」という人物がいたなら,「個人ID」が0001の「井上太郎」とは,同姓同名の別人ということになります。
主キーを追加したことで,テーブル間の関連性を設定する準備ができました。あとは個人情報テーブルに,会社情報テーブルの「会社ID」の値を格納するためのフィールドを追加すればよいのです。このように,ほかのテーブルと関連付けるためのフィールドを外部キーと呼びます(図2)。外部キーには,ほかのテーブルの主キーの値が格納されます。
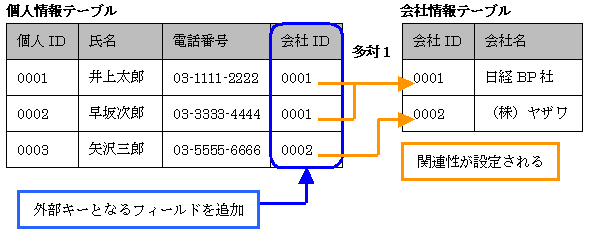 |
個人情報テーブルの「井上太郎」の「会社ID」の値は,0001となっています。会社情報テーブルを見ると,「会社ID」の値が0001なのは「日経BP社」となっています。これによって,「井上太郎」の勤務先が「日経BP社」であることが特定できます。これがテーブル間の関連性です。
関連性を設定するために,会社情報テーブルの側に「個人ID」フィールドを追加してはダメです。なぜだか理由がわかりますか?一つの会社に勤務している人物が複数の場合があるので,「会社情報テーブル」に「個人ID」フィールドを追加したのでは,そこに格納する値が定まらないからです。
●正しい正規化
2つのテーブルを関連付ける場合には,テーブル間のレコードが多対1(または1対多)の関係になるようにします(図3)。たとえば,会社情報テーブルの「日経BP社」という1件のレコードには,個人情報テーブルの「井上太郎」と「早坂次郎」という2件のレコードが関連付けられています。これが正しい正規化です。
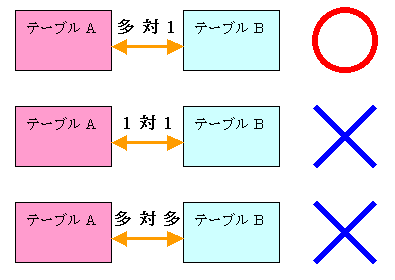 |
もしもテーブル間のレコードの関係が,「1対1」だったり,「多対多」である場合は,正しい正規化とは言えません。「1対1」なら,テーブルを分割した意味がないからです。「多対多」なら,テーブルをもう一つ追加して,二つの「多対1」の関係に分割できます。
●参照整合性とインデックス
(1)必要なデータを洗い出す,(2)フィールドの属性を決定する,(3)テーブルを正規化する,(4)テーブルの関連性を設定する,という作業が終了すれば,データベースの設計は完了です。ただし,市販のデータベース管理システムの多くは,データベースをさらに使いやすくするための機能を提供しています。ここでは,「参照整合性」と「インデックス」を紹介しましょう。これらは,データベースの設計時に考慮すべき機能です。
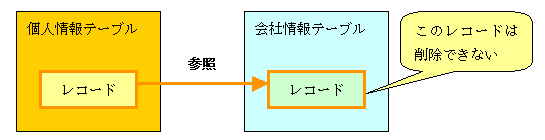
参照整合性とは,迷子のレコードを発生させないようにする仕組みです。たとえば,会社情報テーブルから「日経BP社」のレコードを削除したとしましょう。これによって,個人情報テーブルの「井上太郎」と「早坂次郎」の勤務先は不明(迷子)になってしまいます。このような問題を防ぐために,ほかのテーブルから参照されている間は,レコードを削除できないようにする機能が,参照整合性です。参照整合性を適切に設定すれば,データベースに誤った操作をしてしまうことを防げます(図4)。
 |
インデックスとは,レコードを高速に検索するための仕組みです。実際のデータが格納されたテーブルとは別に,インデックス・テーブルと呼ぶテーブルを作成し,それを使ってレコードを検索します。インデックス・テーブルは,検索対象となるデータを格納したフィールドと,そのデータが実際のテーブルでどの位置にあるかを示す値を格納したフィールドで構成されます(図5)。たとえば,個人情報テーブルを「氏名」で検索するインデックス・テーブルなら,以下のようになります。実際の個人情報テーブルより,インデックステーブルの方がサイズが小さいので,高速に検索できるのです。
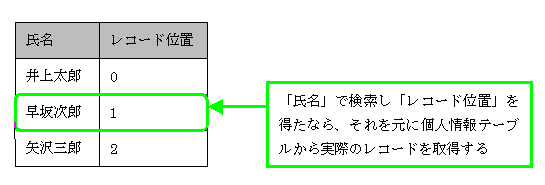 |
インデックスは,テーブルのあらゆるフィールドに対して作成できます。これまでに作成してきた電話帳のデータベースなら,「氏名」「電話番号」および「会社名」で検索するためのインデックスを作成できます。ただし,むやみにインデックスを多くすると,データの書き込み,更新,および削除の処理が遅くなってしまうので注意してください。これらの処理が発生するたびに,インデックス・テーブルが更新されるからです。さらに,インデックス・テーブルの分だけ,データ・ファイルのサイズが大きくなってしまうという問題もあります。
●データベース設計の掟
これまで説明した事項を「データベース設計の掟」としてまとめておきます(図6)。これらの掟を守っていれば,データベースを適切に設計できるはずです。
 |



















































