MSCS(マイクロソフト・クラスタ・サービス)環境でNIC(ネットワーク・インターフェース・カード)のハードウエア障害が発生しました。その際,クラスタ・グループが障害ノードよりスタンバイ・ノードへフェイル・オーバーすると期待していたのですが,実際にはクラスタ・グループ全体が障害によりオフラインになってしまいました。 管理ツールであるクラスタ・アドミニストレータによりこのときの状態を確認すると,両ノードのNICのアイコンに「×」マークが表示されていました。通信障害が発生したことは示していましたが,どちらが障害ノードなのかは判明しない表示でした。NICのハードウエア障害が発生した際には,当該ノードだけが障害とならず,クラスタ・グループ全体が障害となってしまうのでしょうか?
クラスタを構成するネットワークでICMP(インターネット・コントロール・メッセージ・プロトコル)が利用できないとこの現象が発生します。企業によってはネットワーク管理上のポリシーにより,ICMPをルーターなどで禁止していることがあります。具体的には,MCSCを構成するコンピュータからその外のホストに対してping(ICMP Echo Request)を打っても,正しく応答(ICMP Echo Reply)が返ってこない場合が当てはまります。 MSCSはWindows Serverの上位版が標準で備えるフェイル・オーバー・クラスタ機能です。複数のマシンをセットにしてクラスタ・グループを構成し,ハードウエアやOS,ソフトウエアのいずれかに障害が生じた場合,障害が生じたマシンの処理を別のマシンに移してサービスを継続させます。これがフェイル・オーバーと呼ばれる処理です。クラスタ・グループを構成する個々のコンピュータをノードと呼びます。 本来は,NICの障害が発生した際にも正しく障害が認識され,フェイル・オーバーします。しかしながら,ICMPを利用できなくしたネットワーク環境では,ご質問のように当該ノードだけが障害とならず,クラスタ・グループ全体が障害となります。これは,どの部分でネットワーク障害が発生したのか,クラスタ・メンバーだけでは判断できないためです。
pingを通さないとき発生
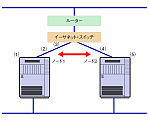
MSCSクラスタ・メンバーは約1.2秒ごとに,互いに3343/udpのユニキャストを送信しています(Windows Server 2003の場合,条件によりマルチキャストを使用します。詳しくはマイクロソフトのサポート技術情報の307962を参照してください)。 相手ノードからの3343/udpパケットが3回(two heartbeat periods)失敗すると,ネットワーク障害が発生したと判断します。 図1でノード1がノード2からの3343/udpパケットの未到達を検出した場合は以下のいずれかの個所に障害が発生したと考えられます。
(1)自ノードのNIC ただし,これらのどこかに問題があることまでは分かりますが,それ以上のことは分かりません。 障害個所をより正確に特定するにはどうしたらよいでしょうか? これには,MSCS以外のホスト,例えばMSCSを構成するコンピュータが所属するサブネットのデフォルト・ゲートウエイ(ルーター)と通信可能かどうかを調べる方法があります。
障害個所の特定にICMPを利用 その一方,図1で両ノードがともにルーターと通信不能であれば,ノードやそこに接続したケーブルの障害というよりは,ネットワーク全体に問題がある可能性が高いことを示唆しています。例えばイーサネット・スイッチの障害などがあり得るでしょう。 実はMSCSは,このような診断を障害時に行っています。具体的にはクラスタ・メンバー以外のホストとして,
・各ノードの経路表上で障害ネットワークに存在するdestination host(通常はそのサブネットのゲートウエイ) をリストアップし,ICMP Echo Request に対してReplyを返してくるかどうかにより,障害が生じた場所を判断しようとします。 そのため,該当するホスト(多くの場合ルーターを含みます)がICMP Echo Replyを返さない場合,ネットワーク全体の障害と判断してしまい,障害ノードの判定に失敗することになります。 このような場合には,MSCSのログであるcluster.logというファイルに図2のような記録が残ります。この中の[NM]はNode Managerからのログであることを示しています。
このログを見ると,pingを送出したNICと,応答すべきホストのIPアドレスが分かります。可能でしたらルーターなどの設定を見直してそのホストに対してpingが通るようにすると今回のような原因でフェイル・オーバーに失敗する問題は解決します。 サポート技術情報242600「2ノードのサーバークラスタにおけるネットワーク障害の検出と回復」も参考にしてください。 小森 博司
日本ヒューレット・パッカード テクノロジーサービス統括本部
サポートデリバリー本部 エンタープライズソリューション本部 ソフトウェアミドルリモートサポート部 シニアエンジニア |