一般的なHadoopシステムが抱える3つの課題とは
ビッグデータ活用に取り組む企業が増えている。データをビジネスに活用するというアプローチは決して新しいものではないが、近年の目覚ましい技術革新によって、これまで分析不可能だった量のデータも分析可能になってきた。そのシステムとして大きな注目を集めているのが、分散配置されたデータを並列処理する「Hadoop」である。

ソリューション事業推進本部
ビッグデータ・アナリティクス部
ビッグデータプラットフォーム課
瓜田 幸代 氏
「私どものお客様でも、通信系や流通系を中心にHadoopを導入されるお客様が増えており、大きな成果を上げています」。このように語るのは、CTCでビッグデータプラットフォームを担当する瓜田氏だ。例えば同社の顧客であるマイクロアドでは、毎日100億件に上るデータをHadoopで分析し、広告配信の効果を向上。その他にも、ネットワーク機器のログ分析に活用することで、分析/運用コストを1/5に削減した事例もあるという。
しかしその一方で、従来のHadoopの構成には問題もある。
「Hadoopでは分析対象となるデータを、分散型ファイルシステムであるHDFSに格納しますが、業務データや機器のログデータは別ストレージ上にあるため、分析するにはHadoop基盤にデータを取り込む必要があります」と瓜田氏は指摘する。このデータの取り込み時間が分析業務のボトルネックになり、数分の分析のために何時間もデータコピーに費やされるケースもあるという。
問題はこれだけではない。HDFSは1つのデータを複数のノードに、デフォルトでは3面ミラーで書き込む。実際の3倍分データ保存容量は必要となるが、これによって冗長性を確保し、1つのノード(DataNode)がダウンしても稼働し続けるように設計されている。しかしHDFS全体のメタデータを格納するNameNodeがダウンすると、HDFS全体がサービス停止に陥ってしまう。つまりHDFSには単一障害点が存在するわけだ。また複数のDataNodeに格納されたデータは、バックアップの取得が難しいという問題もある。
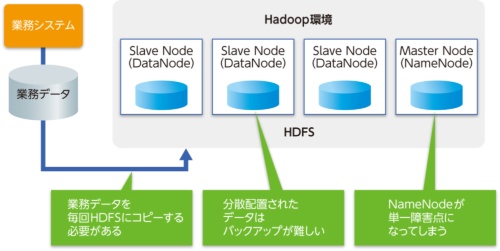
実際にHadoopを使い始めてから、これらの問題に頭を悩ませているユーザーも多いのではないだろうか。