Apache Sparkは複数のサーバーでクラスターを構成して、データを分散処理する技術である。現在、分散データ処理ソフトは「Hadoop」がデファクトスタンダードになっている。Apache Sparkは、Hadoopが搭載する分散データ処理エンジン「MapReduce」の次世代版と位置付けられる。MapReduceが苦手としていた繰り返しの多いデータ処理や、リアルタイムに近いデータ処理を得意とするのが特徴だ。
学生プロジェクトとして開発
Apache Sparkのベースとなる技術はカリフォルニア大学バークレー校で生まれた。現在は同大学からスピンアウトしたメンバーが在籍する米Databricksを中心に、オープンソースソフトとして開発されている。2009年に開発が始まり、2014年5月にバージョン1.0がリリースされた。米Clouderaをはじめ、Hadoopの商用ディストリビューションを提供する企業が、Apache Sparkの商用サポートを開始している。
Apache Sparkは、データをクラスターに配置し、分散処理するという点ではMapReduceと同じである。異なるのは、メインメモリー上で連続してデータ処理を実行していく点だ(図)。MapReduceは、データ処理を実行するたびに結果をディスクに書き込む。そのためデータ処理の回数が増えるほど、ディスクを読み書きするオーバーヘッドが大きくなる。
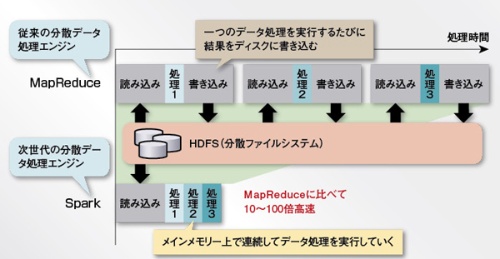
図●次世代の分散データ処理エンジン「Apache Spark」の概要
[画像のクリックで拡大表示]