コンピュータで文字を取り扱う際,文字コードについて知っておく必要があります。特に日本では複数の文字コードが混在して使われる上,プラットフォームによって取り扱う文字の種類も異なることから,状況が複雑になっています。本記事では文字を正しく取り扱うための基礎知識について簡単に紹介します。
コンピュータはすべてのデータを数値として取り扱います。文字を取り扱うときも,数値に対応づけて処理します。
例えば,「ようこそITpro」というテキスト・データをWindows XPのメモ帳で作成し,ファイルに保存します。そのファイルをバイナリ・エディタで開くと写真1のような数値が並んでいることが分かります。各文字と数値は表1のように対応づけられています。

コンピュータ内部で文字を表すのに使う数値を「文字コード」(character code)と呼びます。
文字コードの割り当て方にはさまざまな種類があり,OSやアプリケーションによって異なるものが使われます。同一アプリケーションでも,内部処理に使う文字コード体系と入出力に使う文字コード体系が違うことは珍しくありません。
文字コード体系が違えば,数値と文字の対応が変わります。同一のデータであっても処理するための文字コード体系が違えば,想定外の文字として処理され,文字化けなどが生じてしまいます。
最初に文字集合を規定
それではどのような文字コード体系があるのでしょうか。それを考える前にまず「どのような文字が使われるのか」について知っておかねばなりません。
例えば,英語ではアルファベットや記号類だけを使いますが,日本語では平仮名や片仮名,漢字なども使います。タイ語はタイ文字を使います。
また漢字などは数が非常に多いため,現状ではすべてを使うのは困難です。ですからどの範囲の文字を使うのかをきちんと決めておく必要があります。
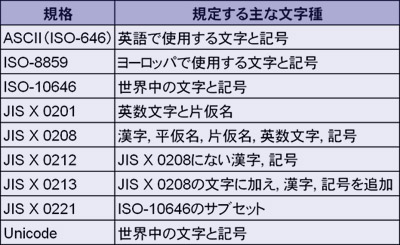
利用する文字の集まりを「文字集合」(character set)と呼びます。文字は情報交換の基盤となるものですから,国家や国際機関が,用途などに応じた文字集合を標準規格として定めています。例えば表2のような規格があります。
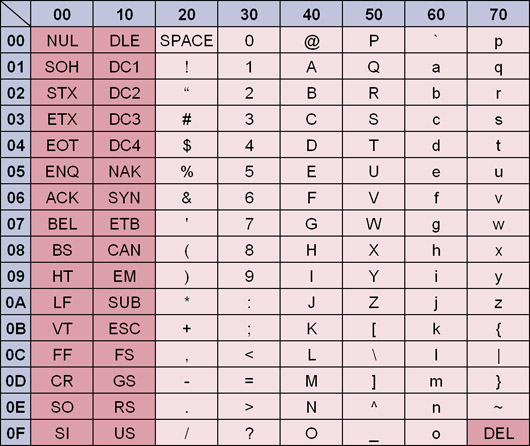
コンピュータで使う文字集合規格のうち,もっとも基本となるのが「ASCII文字集合」です(ASCIIコードまたはANSIコードとも呼びます)。ASCII文字集合では表3のような文字を規定しています。表で分かる通り,7ビットの数値(0~127)ですべての文字を表現できます。元々は,米国の国内標準でしたが,現在は国際標準化機構(ISO)によって国際標準(ISO-646)となっています。
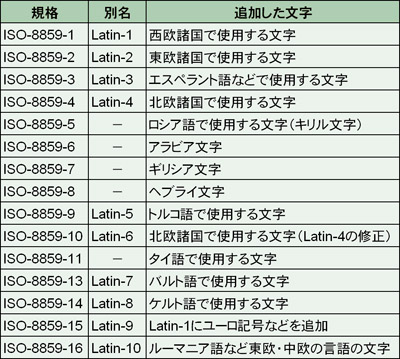
また現在では,ASCII文字集合を8ビットに拡張し,増えた領域にヨーロッパ諸国で使われる文字を定義した「ISO-8859」という文字集合規格も使われます。追加する文字の種類によって表4のような規格があります。
日本語の場合は日本工業規格(JIS)の「JIS X 0201」と「JIS X 0208」という文字集合規格が基本となります。
JIS X 0201は,ASCII文字集合を8ビットに拡張し,増えた領域に片仮名文字を定義したものです(この片仮名文字がいわゆる「半角カナ」)。また,ASCII文字集合の一部の文字を変更しています。具体的には「\」(バックスラッシュ)を「¥」(円記号)に,「~」(チルダ)を「 ̄」(オーバーライン)に変更しています。
JIS X 0208では,平仮名や各種記号類,漢字約6000字を定義しています。アルファベットや数字も定義されています(いわゆる全角英数文字)。
また,JIS X 0208とは別の約6000字の漢字を定義した「JIS X 0212」という規格もあります。この文字集合は「JIS補助漢字」などと呼ばれます。なおJIS補助漢字にはJIS X 0208の文字は含まれません。
JIS X 0208に文字を追加した拡張規格が「JIS X 0213」です。JIS X 0208の文字に加えて,約4000字が追加されています。追加文字には,JIS補助漢字のうち使用頻度が高いものも入っています。
2000年に制定されたことから「JIS2000」,2004年に改訂されたものは「JIS2004」などとも呼ばれます。




































![Word 最速時短術 [増補新版]](https://info.nikkeibp.co.jp/atclnxt/books/25/03/07/00396/B_9784296207329.jpg)









