■電子文書の標準的なフォーマットとしてPDFファイルが浸透してきた。しかし,ときには蓄積したPDFファイルから,それを再編集・加工して新しい文書ファイルを作らなければならないことがある。そのようなニーズに応えてくれるツールとして,PDFファイルをMicrosoft WordのDocファイルに変換するソフトを紹介する。
インターネット上で公開されている文書や,配布/回覧される文書などでPDF形式が広く使われている。社内の標準文章形式をPDFにしている企業も多い。閲覧に必要な「Acrobat Reader」の無償公開も理由の1つだが,以前取り上げたPDF作成ソフトの低価格化が普及の後押しをしている(該当記事)。
PDFファイルを受け取る機会が増えると,それを利用して「PDF文書を変更したい」という要望が出てくる。「可能ならば,元の文書ファイルが欲しい」と思った読者も多いだろう。そこで,PDFファイルからWordファイルを生成する変換ソフト3本を取り上げ,使い勝手と再現精度を比較した(表1)。
| ||||||||||||
| 表1●今回取り上げたPDF文書からWord文書を作成するソフト |
3つのファイルで変換精度を検証
ソフトの変換精度を検証するのに,3種類のWordファイルを用意した。
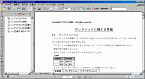
サンプル1:表を含む技術文書
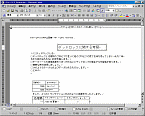
Word形式の技術文書を「Acrobat 7.0」を使い作成したPDFファイル。「しおり」や「添付ファイル」機能を使用している(図1)。
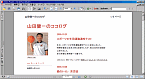
サンプル2:画像を含むWeb画面
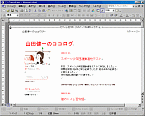
筆者のブログをInternet Explorer(IE)で表示させ,「Acrobat 4.0」を使いPDF化(図2)。
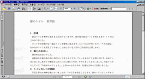
サンプル3:印刷文書をスキャンした画像
印刷した文書をキヤノン製のフラットベッド・スキャナ「CanoScan LiDE50」で読み込み,付属する「CanoScan Toolbox 4.1」でPDF化した(図3)。読み取り時の解像度は300dpi。
 △ 図をクリックすると拡大されます |
 △ 図をクリックすると拡大されます |
 △ 図をクリックすると拡大されます |
| 図1●サンプル1 | 図2●サンプル2 | 図3●サンプル3 |
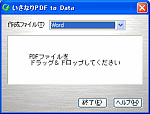
低価格でシンプルなUIの「いきなりPDF to Data」
 △ 図をクリックすると拡大されます |
| 図4●いきなりPDF to Dataのユーザー・インターフェース |
元のPDFファイルのあった場所に,PDFファイル名の拡張子が除かれたフォルダが作成され,その中にWord文書が生成される。変換の途中で「Acrobat」もしくは「Adobe Reader」が起動されるが,変換が終了すると自動的に閉じられWordが起動する。作成されたWord文書のイメージは図5から図7のようになった。
 △ 図をクリックすると拡大されます |
 △ 図をクリックすると拡大されます |
 △ 図をクリックすると拡大されます |
| 図5●サンプル1をいきなりPDF to DataでWordファイル化 | 図6●サンプル2をいきなりPDF to DataでWordファイル化 | 図7●サンプル3をいきなりPDF to DataでWordファイル化 |
これらの結果から分かるようにレイアウトはテキスト・ボックスを用いて再現している。また,メーカーのホームページに記載があるように,このソフトはPDFファイルに含まれるテキスト・データを使わずに,OCR(光学式文字認識)処理している。そのため,他の2本と比較して誤変換が多かった。サンプル1の変換結果の1ページ目の誤読には次のようなものがあった。
|
正:All 誤:A11 正:1-1 誤:1・1 正:データがある 誤:データかおる 正:1-2 誤:1・2 正:Oracle 誤:0racle 正:Oracle 誤:Orade 正:Oracle 誤:Orade 正:/* 000.SQL */ 誤:/゛000.SQL゛/ 正:-- データの確認 誤:一一データの確認 正:-- 接続 誤:一一接続 正:SCOTT/TIGER@ORCL 誤:SCOTT/TIGER 正:EMPNO,ENAME 誤:EMPN0,ENAjxlE |
OCRソフトでよく見られる認識ミスである。この中には,半角文字が全角文字として認識されたものは含めていないが,該当するものは多かった。そのため,プログラミングの解説文書の変換などには向かない。サンプル2では,画像データ中に文字が含まれていると判断されている。サンプル3は,文字の色が正しく認識されていない。



















































