エンコーディングにはUnicodeを使うのが基本
最後にエンコーディングについて見てみよう。Windows Vistaで追加された文字は,Unicodeでしか扱えない。シフトJISではキャラクタ・コードが割り当てられていないからだ。実際には,JIS2004で扱えるJIS第3/第4水準の文字についてもキャラクタ・コードを割り振った「シフトJIS2004」や「EUC2004」などのエンコーディングがある。ただしこれらは「標準(Standard)」ではない。また,シフトJIS2004では,従来のシフトJISの空いているコード領域にJIS第3/第4水準の文字を割り当てているため,Windowsの外字領域と重なっている文字がある。マイクロソフトは,標準でないこと,外字領域と重なっていること,そしてWindowsのコード・ページを今後増やさない方針であることを理由に,シフトJIS2004には対応しないという。Windowsでは,エンコーディングの基本はUnicodeだ。
なお,Unicodeでしか扱えない文字が存在するのは,Windows Vistaに始まったわけではない。Windows 98/Windows NT 4.0 SP4は,JIS X 0212(補助漢字)に対応しているが,これらの追加された文字は既にUnicodeでしか扱えなかった。
一方,Unicode(UTF-16)では,1文字当たり2バイトのキャラクタ・コードが割り当てられているが,中には4バイトのキャラクタ・コードが割り当てられている文字がある。Windows Vistaで追加された文字の中には4バイトの文字があり,これが原因でシステムが不具合を起こすと懸念されるかもしれないが,通常は問題ないと思われる。その理由は次の通りだ。
まず,通常2バイトのキャラクタ・コード体系で1文字当たり4バイトにするための拡張コードを「サロゲート・ペア」と呼ぶ。2バイトで扱える文字種6万5536文字を超える文字数を扱うために利用する。Windows Vistaはもちろん,Windows XP/2003もサロゲート・ペアに対応している。そのため,APIを利用して文字を処理しているアプリケーションは,サロゲート・ペアも正しく処理できるはずだ。
Backspaceを使ったサロゲート・ペアの削除では仕様を変更
例えばWindows XPのメモ帳で,「叱」の正字(キャラクタ・コードはUTF-16でD842 DF9F)を,OpenTypeフォントのMSゴシックで表示すると,1つの「・」が表示される(図2)。これはWindows XPのMSゴシックにグリフがなく,フォント・リンク機能でもほかのフォントからグリフを代用できないために「・」と表示されているだけで,正しく処理されている。
ただし,Windows XP/2003とWindows Vistaでは,サロゲート・ペアに関する処理の仕様が変わった部分がある。Windows XPでは,上記「・」(「叱」の正字)の左側にカレットを移動させてdeleteキーを押すと1文字(4バイト)が削除されるのに対して,「・」の右にカレットを移動してBackspaceキーを押すと下位2バイト分しか削除されない。マイクロソフトによると,これはサロゲート・ペアを正しく処理していないのではなく,Windows XPの仕様だという。後で説明するように,この部分の処理の仕様がWindows Vistaでは変わっている。
Unicodeでは,2つの文字を組み合わせて1つの文字として表示するものがある。例えば「は」と「゛」の2文字で「ば」を表すようなものである(実際には「ば」はUnicodeでも「は」や「゛」とは独立した文字として登録されているので,通常「ば」が4バイトで表現されることはない)。Windowsでは,このような文字の組み合わせ処理を,Uniscribe(Unicode Script Processor)と呼ぶモジュールが担っている。ヨーロッパの言語で使われているアクセント付きのアルファベットを,ベースとなるアルファベットとアクセントの2文字を組み合わせて1文字として表示したり,中東の言語のように文脈によって形が変わる文字を描画する際に,特定のUnicodeの列に対してそれらがどのような形になるのかをUniscribeがOpenTypeフォントに問い合わせ,文字の形を決めてからGDI(Graphics Device Interface)に渡している。
Windows XPでは,Uniscribeが合成した文字の右側でBackspaceキーが押された場合,例えば「は」と「゛」の組み合わせで「ば」を表示しているときには,下位2バイトの「゛」のみを削除するような仕様になっている。「ぱ」を入力するときに「ば」とタイプミスした場合は,Backspaceを1回押すことで「゛」を「゜」に入力し直せるようにしているわけだ(これは合字の例としてひらがなを挙げているだけで,実際には「ば」の右でBackspaceキーを押すと「ば」全体が削除される)。Windows XPでは,サロゲート・ペアを使った文字も2文字分(4バイト)で1文字を表現しているという点で,同じ振る舞いにしているという。ただ,「ば」のような合字とサロゲート・ペアとは,どちらも4バイトで1文字とはいうものの,成り立ちは違う。Windows XPのようにBackspaceを押したときに,サロゲート・ペアに相当する上位2バイトだけが残るのは不自然だ。そこでWindows Vistaでは,サロゲート・ペアを使った文字では,Backspaceで4バイト分を削除する仕様に変更したという。
一方,同じ文字(「叱」の正字)を,FixedSysなどのビットマップ・フォントを使ってメモ帳で表示すると「■■」と,2文字分が表示される。ビットマップ・フォントは,コード体系がANSI(シフトJIS)だからだ。処理できないエンコーディングでその文字を表示しようとしているために,このような振る舞いになっている。
ちなみに,Windowsが備えるUnicodeからANSI(シフトJIS)へのキャラクタ・コード変換APIであるWideCharToMultiByte関数や,.NET FrameworkのSystem.Text.Encodingクラスを利用して,サロゲート・ペアを使った4バイト文字をシフトJISに変換しようとすると「??(3F 3F)」という2文字(2バイト)が返ってくる(図3)。そのため,ビットマップ・フォントで表示すると,2文字分の「■■」が表示される。
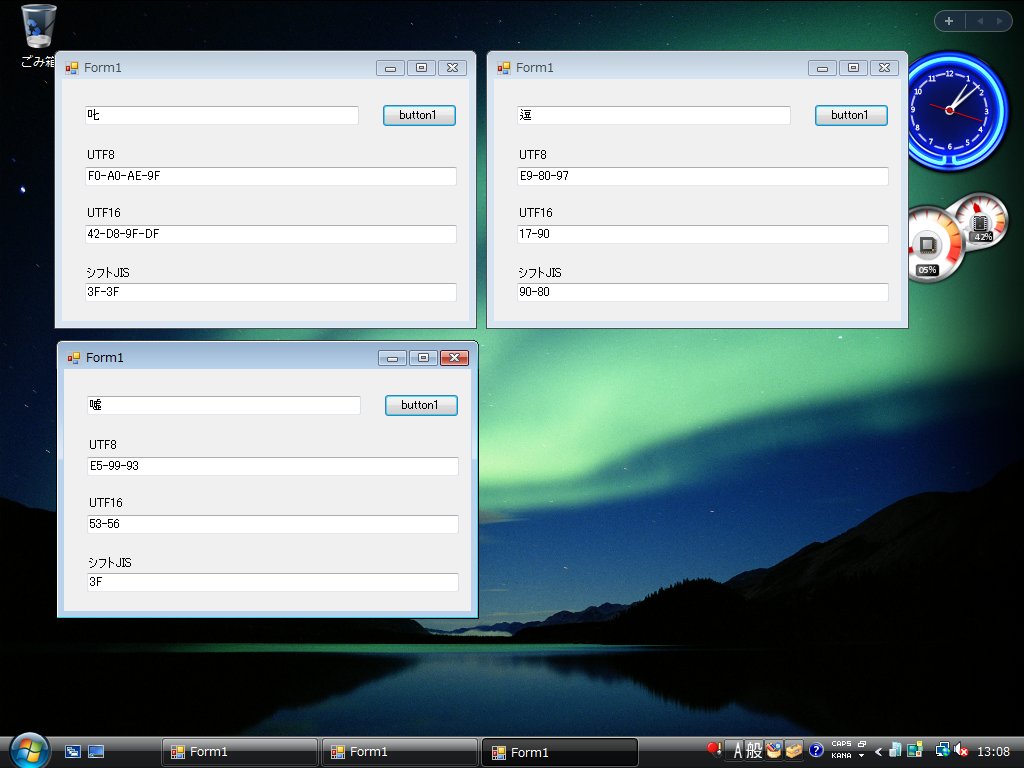 |
| 図3●「叱」の正字(左上),「嘘」の正字(左下),2点しんにょうの「逗」のキャラクタ・コードを,独自に作ったサンプル・プログラムで調べた。利用したのは.NET FrameworkのSystem.Text.Encodingクラス。UTF16エンコーディングで表示されているキャラクタ・コードの上位と下位が反転しているのはリトル・エンディアンを指定したため [画像のクリックで拡大表示] |
このとき,カレットは2つの「■」の間に移動できる。この振る舞いは,サロゲート・ペアを正しく処理できていないのではなく,仕様であるという。なぜなら,画面上は「■■」の2文字として表示されているのだから,その間にカレットが移動できるべきだとしている。ちなみに,この処理もUniscribeが担っている。
デフォルトをシフトJISにしていると問題
以上をまとめると,字体に関しては,JIS2004またはJIS90のどちらかに統一すれば問題ない。JIS2004に統一したときは,JIS90タグによって同一キャラクタ・コードでJIS2004の字体と同時にJIS90の字体も表示できる。ただしこれは,Windowsに標準で付属するMSゴシックなどのフォントを利用したときだけである。市販のフォントを使用したときは,そのフォントが採用している字体で表示される。
Unicodeでしか表現できない追加文字に関しても,恐らく問題は起きない。なぜならこれは,既にWindows 98/NT4.0 SP4のときからそうであるからだ。今まで問題が起きていないならば,恐らくWindows Vistaでも問題は起きないだろう。ただし,Windows Vista以外では,使用するフォントにその文字のグリフがない場合には,正しく表示されないことがある。
サロゲート・ペアについても大丈夫だ。Windows 2000以降はサロゲート・ペアに対応している。ただし,Windows 2000では,デフォルトで対応機能がオフになっており,レジストリを書き換えてこの機能をオンにする必要があった。標準でサロゲート・ペアに対応したのはWindows XPである。
なお,問題が生じるとしたら,デフォルトのエンコーディングをANSI(シフトJIS)としているアプリケーションだろう。例えばExplorerに統合されているzip機能だ。zipファイル内のファイル名はANSIエンコーディングと定められている。そのためUnicodeでしか表現できない文字をファイル名に付けると,zipファイル内に格納できずエラーになる(図4)。ただし,繰り返すが,これはWindows Vistaに始まったことではない。Windows XPでも同様である。
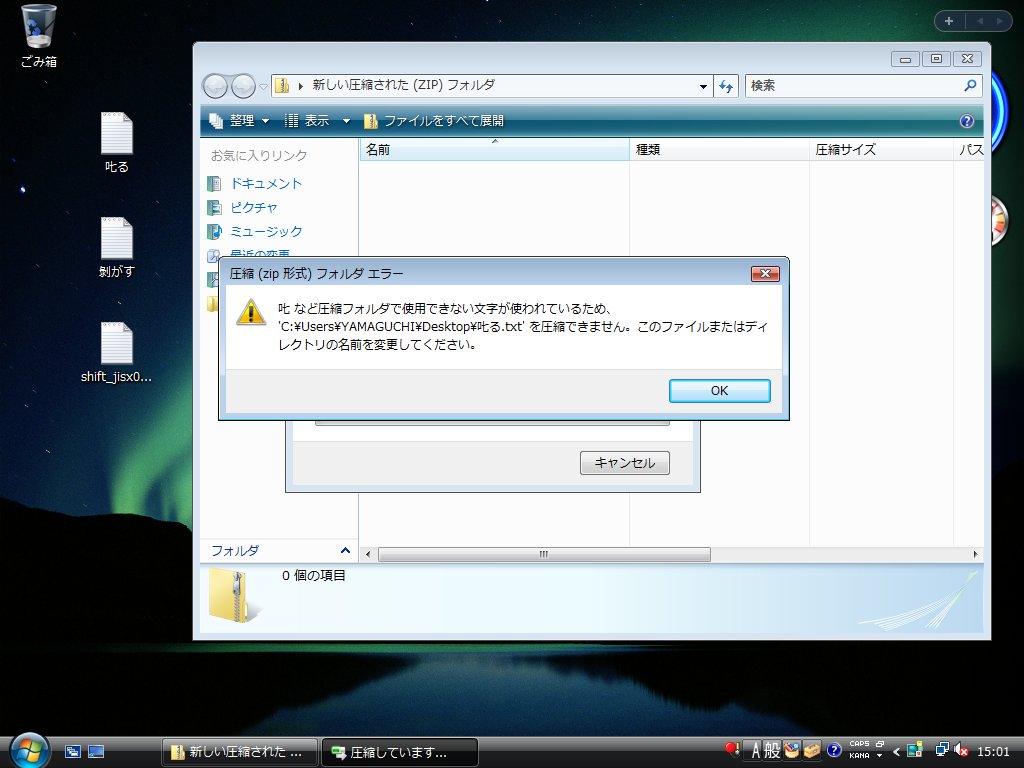 |
| 図4●シフトJISで表現できない「叱」の正字をファイル名に含んだファイルをzipファイルに格納しようとしたところ [画像のクリックで拡大表示] |
なお,Explorerに統合されているzip機能をUnicode対応に拡張すれば格納できるようになるが,マイクロソフトが勝手に仕様を拡張するとほかのzip対応ソフトとの相互運用性(インターオペラビリティ)が損なわれる。ちなみにマイクロソフトが定めたデータ圧縮の仕様であるCAB形式は,Unicodeに対応している。



















































